Enterprise (Contact for Pricing): Custom deployment, advanced customization, white-label solutions, dedicated instance, 24/7 support, analytics, team collaboration, enterprise SLA
FAQ
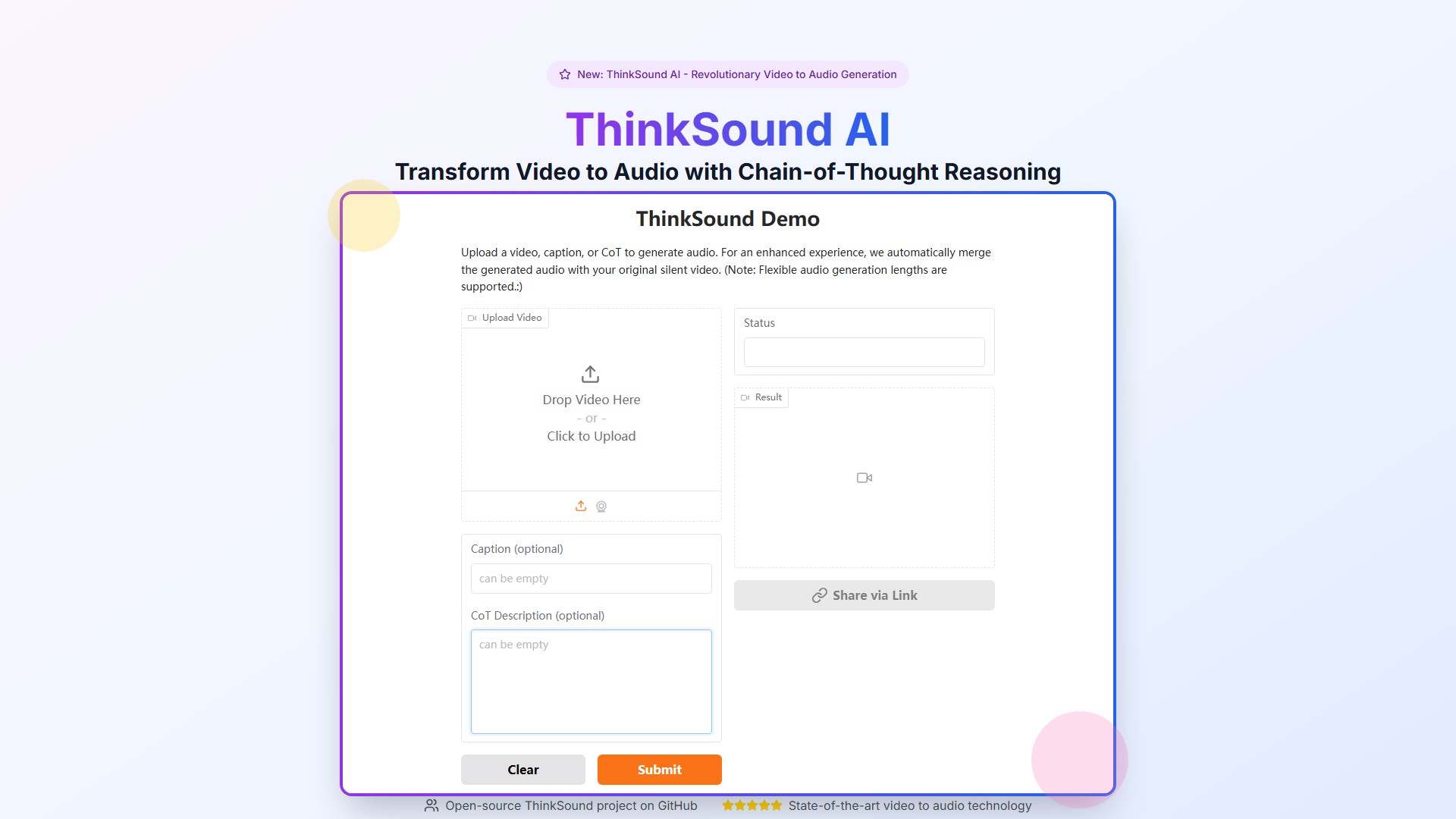
How it works: Uses Chain-of-Thought reasoning to convert video to audio through three stages: foundational foley generation, object-centric refinement, natural language editing
Model access: Open-source project with models, AudioCoT dataset, and examples available on Hugging Face and GitHub
Uniqueness: First video to audio framework using Chain-of-Thought reasoning, understands visual context and generates semantically coherent soundscapes
API availability: Currently in research phase, commercial API coming soon