ThinkSound AI
Key Features
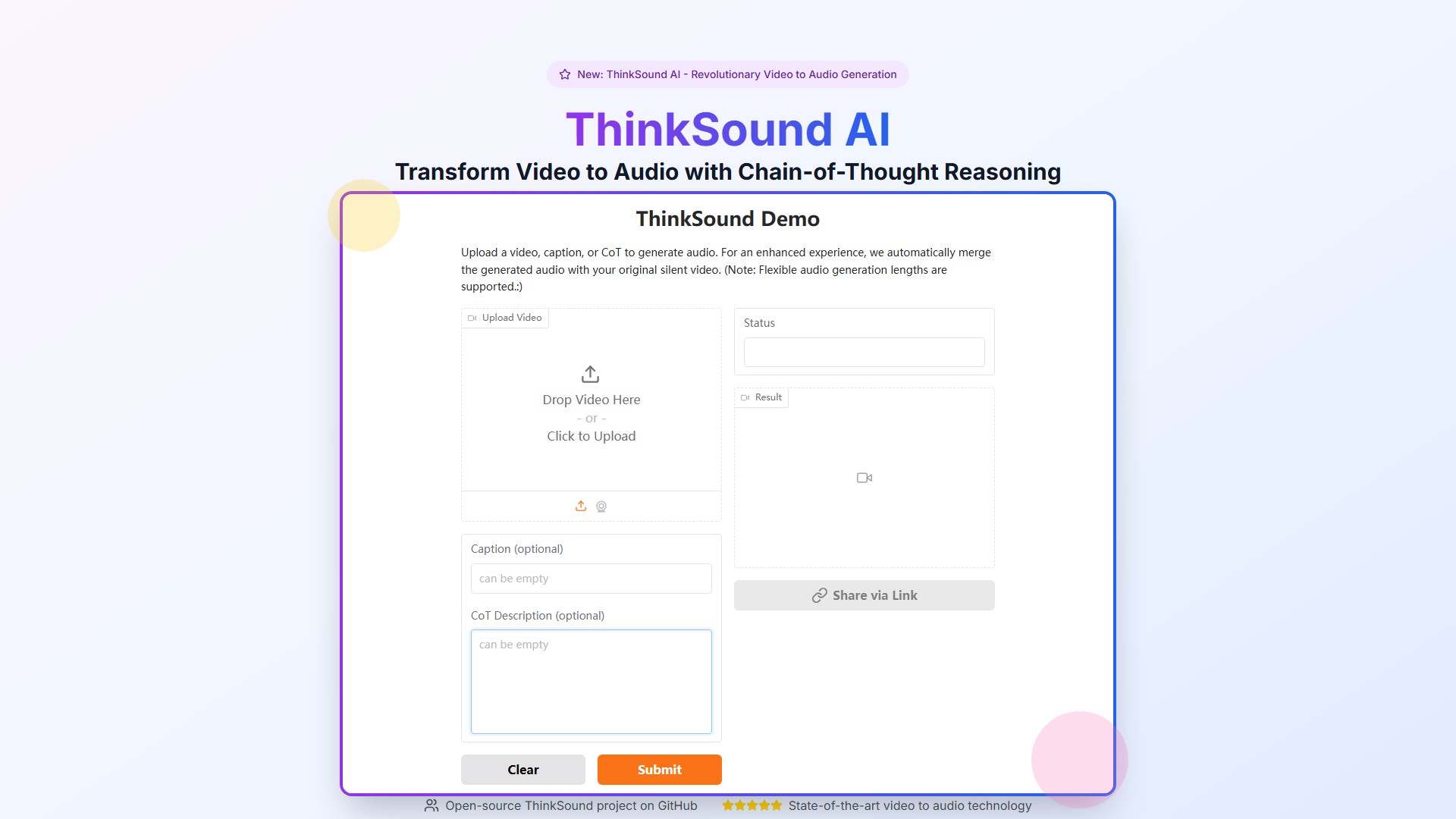
- Video to Audio Generation: Transform any video into professional soundscapes with Chain-of-Thought AI
- Three-Stage Process: Foundational foley generation, object refinement, and natural language editing
- AudioCoT Technology: Structured reasoning annotations for semantically coherent video to audio conversion
- Interactive Refinement: Edit and refine video to audio output with simple natural language instructions
- Open-Source Platform: Access complete video to audio models and datasets on Hugging Face and GitHub
How It Works
- Upload Video: ThinkSound AI analyzes visual content using multimodal understanding
- Chain-of-Thought Analysis: Decomposes video into audio elements, identifying objects, actions, and ambient sounds
- Three-Stage Audio Generation: Foundational foley sounds, object-centric refinement, natural language editing
- Interactive Refinement: Precise control over every audio element with natural language instructions
Target Users
- Researchers: Research access for exploring video to audio technology
- Developers and Creators: Developer access with API and advanced features
- Organizations: Enterprise solutions requiring custom video to audio deployments
Core Advantages
- First video to audio framework using Chain-of-Thought reasoning
- Understands visual context and generates semantically coherent soundscapes
- Interactive refinement capabilities for precise audio control
- Open-source project with complete models and datasets access
- Supports 20+ languages, 44.1kHz audio quality
Pricing Plans
- Research Access (Free): Research access, generation examples, AudioCoT dataset, GitHub repository, community support (research use only)
- Developer Access (Coming Soon): API access, advanced Chain-of-Thought features, custom generation, priority processing, developer support, commercial license, model fine-tuning, integration guides
- Enterprise (Contact for Pricing): Custom deployment, advanced customization, white-label solutions, dedicated instance, 24/7 support, analytics, team collaboration, enterprise SLA
FAQ
- How it works: Uses Chain-of-Thought reasoning to convert video to audio through three stages: foundational foley generation, object-centric refinement, natural language editing
- Model access: Open-source project with models, AudioCoT dataset, and examples available on Hugging Face and GitHub
- Uniqueness: First video to audio framework using Chain-of-Thought reasoning, understands visual context and generates semantically coherent soundscapes
- API availability: Currently in research phase, commercial API coming soon
価格設定モデル:
Contact for Pricing
Free
Paid
議論する