一、前言
自2023年5月,阿布扎比技术创新研究所(TII)发布了两个预训练的LLM:Falcon 7B和Falcon-40B,这两个模型的表现十分优异,在OpenLLM排行榜上高居榜首。然而,在短短不到几个月的时间,研究所又推出了第三个重量级的大语言模型——Falcon 180B。
以下是有关 Falcon 180B 的一些主要特点:
- 使用精选语料库增强的 RefinedWeb 的 3.5 万亿个Token进行预训练 (RefinedWeb)
- 使用 Apache 2.0 许可证分发
- 模型大小为 360 GB
- 需要至少 400GB 内存才能使用 Falcon-180B 快速运行推理
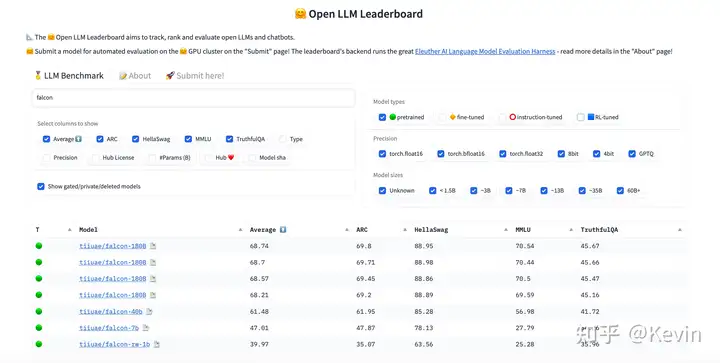
- 在 OpenLLM 排行榜上排名第一(截至 2023 年 9 月 21 日):
我们可以在 Hugging Face Hub 上找到该模型(基础模型和聊天模型),并在 Falcon 聊天演示空间上与该模型进行交互。
在能力方面,Falcon 180B 在自然语言任务上取得了最先进的结果。它在(预训练的)开放访问模型排行榜上名列前茅,并可与 PaLM-2 等专有模型相媲美。虽然还很难确定排名,但它被认为与 PaLM-2 Large 相当,使 Falcon 180B 成为众所周知的最有能力的LLM之一。
Falcon 180B 应该算是在大语言模型开源领域参数量最庞大的免费且可商用的模型了。这无疑是个划时代的成就,但面对LLM需要高昂的计算资源成本,普通用户能否在自己的电脑上运行这样大的模型呢?本文接下来将为你解析Falcon 180B 在消费级硬件上的方案,让让我们一起来感受它强大的力量。
二、Falcon-180B 是什么
Falcon 180B 使用 Amazon SageMaker 在多达 4096 个 GPU 上同时进行了 3.5 万亿个令牌的训练,总共花费了约 7,000,000 个 GPU 小时。这个大型语言模型拥有惊人的1800 亿参数量,它的参数比Llama 2 70B多2.5倍,比Falcon 40B还要多出4.5倍之多。
Falcon 180B 的数据集主要由来自RefinedWeb 的网络数据组成(~85%)。此外,它还接受了对话、技术论文和一小部分代码(~3%)等精选数据的混合训练。这个预训练数据集足够大,即使 3.5 万亿个代币也不足以构成一个纪元。
三、为什么使用 Falcon-180B
Falcon-180B 是目前最好的开源免费的模型,也是最好的模型之一。 Falcon-180B 优于 LLaMA-2 70B、StableLM、RedPajama、MPT和 OpenAI 的 GPT-3.5 等。 Falcon 180B 通常位于 GPT 3.5 和 GPT4 之间,具体取决于评估基准。请参阅 OpenLLM 排行榜。
- 它具有针对推理进行优化的架构,具有多重查询(Shazeer 等人,2019)。
- 它是在允许商业用途的许可下提供的。
- 这是一个原始的预训练模型,应该针对大多数用例进行进一步微调。如果您正在寻找更适合以聊天格式获取通用指令的版本,我们建议您查看 Falcon-180B-Chat。
Falcon 180B 在 Hugging Face 排行榜上得分为 68.74,是得分最高的公开发布的预训练 LLM,超过了 Meta 的 LLaMA 2(67.35)。
四、在消费类硬件上运行 Falcon-180B 的条件
除非你的计算机已经具备了支持密集计算的硬件能力,否则无法开箱即用地运行 Falcon 180B。想要在消费类硬件上运行Falcon-180B模型,您需要进行以下步骤:
- 升级计算机配置:首先,确保你的计算机具备足够的性能来支持运行Falcon-180B模型。这可能需要升级处理器、内存和显卡等硬件组件。按常规标准模型,需要一台 400 GB 的设备,例如 5 个 A100 GPU 和 80 GB VRAM。
- 使用量化版本的模型:为了降低硬件要求,您可以考虑使用Falcon-180B的量化版本。量化模型在基准测试中表现相似,但参数规模更小,对硬件资源的需求较低。查看Open LLM排行榜中的结果,以获取有关量化模型性能的更多信息。
- 优化技术:还有一些优化技术可帮助降低硬件要求。例如,您可以使用混合精度训练(mixed precision training)来利用半精度浮点数计算,从而加快模型训练和推理速度。此外,还可以使用分布式训练和推理技术来利用多台计算机或GPU进行并行计算,提高效率。
量化的 Falcon 模型在基准测试中保留了类似的指标。评估 torch.float16 、 8bit 和 4bit 时的结果相似。查看 Open LLM 排行榜中的结果。
在本文中,我将解释如何在消费类硬件上运行 Falcon-180B。我们将看到在现代计算机上运行 1800 亿个参数的模型是相当经济的。下面还讨论了几种有助于降低硬件要求的技术。
五、如何在消费级硬件上加载 Falcon 180B
5.1、确定加载模型的内存需求
Falcon 180B 有 1800 亿个参数存储为 bfloat16。 (b)float16 参数在内存中占 2 个字节。
当加载模型时,标准 Pytorch pipeline 的工作方式如下:
- 创建一个空模型:180B 参数 * 2 字节 = 360 GB
- 将其权重加载到内存中:180B 参数 * 2 字节 = 360 GB
- 将步骤 2 中加载的权重加载到步骤 1 创建的空模型中
- 将步骤3获得的模型移动到用于推理的设备上,例如GPU
步骤1和步骤2是消耗内存的。总共,您需要 720 GB 可用内存。也可以是 CPU RAM,但为了快速推理,一般建议推荐使用 GPU,例如具有 80 GB VRAM 的 9 A100。
无论是 CPU RAM 还是 VRAM,都需要大量内存。下面来看看用什么方式可以降低这种内存资源要求。
5.2、使用 Hugging Face Hub 上的 safetensors 格式进行分发
在 Hugging Face Hub 上,Falcon 180B 使用 safetensors 格式进行分发。与标准PyTorch格式相比,safetensors格式几乎不需要复制操作,因此模型可以直接加载到之前创建的空模型中,从而节省了大量内存。
关于safetensors
safetensors 可以节省内存,但也使模型运行起来更安全,因为无法以这种格式存储任意代码。 safetensors 模型的加载速度也快得多。从中心下载模型时,建议使用此格式而不是“.bin”格式,以实现更快、安全且节省内存的加载。
从官方通过加载 gpt2 权重将 safetensors 与 PyTorch 进行比较。运行 CPU 和 GPU 基准测试结果:
在 CPU 上,safetensors 比 pytorch 快:76.6 倍
在 GPU 上,safetensors 比 pytorch 快:2.1 倍
虽然看起来我们跳过了第 2 步,但仍然会产生一些内存开销。根据TII在型号卡上的说法,需要400GB的内存来运行Falcon-180B模型。这个要求远远超出了消费者级别的配置,但却比使用标准 Pytorch 格式少了 220 GB。
所以我们需要一台 400 GB 的设备,例如 5 个 A100 GPU 和 80 GB VRAM。这个要求距离我们消费级的配置还很远。
5.3、将 Falcon 180B 拆分到多个存储设备上
我们可能没有一台 400 GB 的内存设备,但是如果可以将多种不同的内存设备组合起来,您的计算机可能拥有超过 400 GB 的内存:
- GPU VRAM:如果您有 NVIDIA RTX 3090 或 4090,则已经是 24 GB。
- CPU RAM:大多数现代计算机至少具有 16 GB CPU RAM。 CPU RAM 的扩展也非常便宜。
- 硬盘驱动器(或 SSD):可能有几 TB 的可用内存。请注意,如果您打算使用 SSD(NVMe M2 类型)运行 LLM,它会比典型的硬盘驱动器快得多。
为了充分利用可用设备,我们可以拆分 Falcon 180B,以便它按优先级顺序使用设备的最大可用内存:GPU、CPU RAM 和硬盘驱动器。
使用 Accelerate 库中的 device_map 功能,将模型的不同层放置在不同的设备上。这样,模型的一部分将在GPU VRAM上运行,另一部分将在CPU RAM上运行,剩余部分将在硬盘驱动器上运行。
device_map 非常方便避免 CUDA 内存不足错误。但如果您计划在消费类硬件上使用 Falcon 180B,那还远远不够理想。即使采用 24 GB VRAM 和 32 GB CPU RAM 的高端配置,也会在硬盘上留下数百 GB 的空间。
这是一个问题,有两个原因:
- 硬盘和 SSD 比 VRAM 和 CPU RAM 慢得多。从硬盘加载并运行 Falcon 180B 需要很长时间。
- 消费类硬盘和 SSD 并未针对这种密集使用而设计和测试。如果模型的许多部分被卸载到硬盘上,则系统在推理过程中必须多次访问和读取模型的巨大分割。这是长时间的大量读取操作。如果您进行数天的推理,例如生成一些合成数据集,这可能会损坏您的硬盘或至少显著缩短其预期寿命。
为了避免过度使用硬盘,我们可以考虑以下的解决方案:
- 添加一个 GPU:大多数高端主板可以容纳两个 RTX 3090/4090。它将为您提供 48 GB 的 VRAM。
- 扩展 CPU RAM:大多数主板都有 4 个可用于 CPU RAM 套件的插槽。 4*128GB CPU RAM 套件已出售,但不容易找到,而且价格仍然昂贵。注意:您的操作系统可以支持的 CPU RAM 总量也有限制。对于 Windows 10,为 2 TB。如果您有较旧的操作系统,则应在购买更多 RAM 之前查看其文档。
- 量化 Falcon 180B 并扩展 CPU RAM。
Falcon 180B 的模型量化是减少其内存消耗的最佳选择之一。
六、通过量化减小 Falcon 180B 的尺寸
现在,将非常大的语言模型量化到较低的精度是常见的做法。 GPTQ 和 bitsandbytes nf4 是将 LLM 量化为 4 位精度的两种流行方法。
6.1、关于 GPTQ 量化技术
Hugging Face Optimum 团队与 AutoGPTQ 库合作,提供了一个简单的 API,可在语言模型上应用 GPTQ 量化。通过 GPTQ 量化,LLM 可以开放为 8 位、4 位、3 位甚至 2 位,以便在较小的硬件上运行它们,而不会大幅降低性能。
GPTQ 是一种训练后量化方法,用于压缩 LLM,与 GPT 类似。 GPTQ 通过减少模型中存储每个权重所需的位数来压缩 GPT 模型,从 32 位减少到仅 3-4 位。这意味着模型占用的内存要少得多,因此它可以在更少的硬件上运行,例如适用于 13B Llama2 型号的单 GPU。 GPTQ 分别分析模型的每一层,并以保持整体准确性的方式近似权重。
使用 GPTQ 的主要好处是:
- 将模型的权重逐层量化为 4 位而不是 16 位,这将所需的内存减少了 4 倍。
- 量化是逐步进行的,以尽量减少量化造成的精度损失。
- 实现与 fp16 模型相同的延迟,但内存使用量减少 4 倍,有时由于自定义内核而更快,例如埃克斯拉玛
- 量化的权重可以保存到磁盘以进行时间头量化。
注意:GPTQ 量化目前仅适用于文本模型。此外,量化过程可能需要很多时间。如果还没有您要使用的模型的 GPTQ 量化版本,请检查 Hugging Face Hub。
6.2、使用量化技术减小模型尺寸的方法
Falcon 180B 使用 bfloat16。我们看到它是 360 GB。一旦量化到 4 位精度,它只有 90 GB(1800 亿个参数 * 0.5 字节)。我们可以加载 4 位 Falcon 180B 和 100 GB 内存(90GB + 一些内存开销)。
如果您有 24 GB 的 VRAM,则“仅”需要 75 GB 的 CPU RAM。它仍然比加载原始模型便宜很多,但更便宜,并且在推理过程中它不会卸载硬盘上的模型层。注意:您仍需要 100 GB 的硬盘可用空间来存储模型。
您甚至不需要 GPU。借助 128 GB CPU RAM,您可以仅使用 CPU 进行推理。
量化本身的成本极高。值得庆幸的是,我们已经可以在网上找到量化版本。 TheBloke 发布了用 GPTQ 制作的 4 位版本:
- 4-bit Falcon 180B
- 4-bit Faclon 180B Chat
虽然模型的精度有所降低,但根据 Hugging Face 的实验,模型的性能保持相似。
GPTQ模型的推理速度非常快,您可以使用LoRA适配器进行微调。虽然可以对GPTQ模型进行微调,但并不推荐这样做。相比之下,使用QLoRA进行微调具有类似的内存消耗,但由于使用了更好的nf4量化方法,因此可以产生更好的模型效果,这一点在QLoRA论文中有所体现。
七、总结
综上所述,要在价格合理的计算机上运行Falcon 180B,您需要进行量化,并拥有至少100GB的内存。为了实现快速推理或微调,您需要使用GPU。RTX 4090是一个不错的选择,但RTX 3090 24GB的价格更实惠,速度较慢。如果您的机箱足够宽敞,您甚至可以安装两张RTX卡。
如果您只有CPU而没有GPU,那么请不要尝试微调,因为速度会非常慢。尽管推理速度也会很慢,但如果您使用最新的高端CPU和针对更快速推理进行优化的软件(例如llama.cpp),那么在仅有CPU的配置下运行Falcon 180B是可能的。
八、References
- Falcon-180B
- https://huggingface.co/tiiuae/falcon-180B
- Falcon-180B-Chat
- https://huggingface.co/tiiuae/falcon-180B-chat
- 4-bit Falcon 180B
- https://huggingface.co/TheBloke/Falcon-180B-GPTQ
- 4-bit Faclon 180B Chat
- https://huggingface.co/TheBloke/Falcon-180B-Chat-GPTQ
- Safetensors
- https://huggingface.co/docs/safetensors/index
- RefinedWeb
- https://huggingface.co/datasets/tiiuae/falcon-refinedweb
- TheBloke HF
- https://huggingface.co/TheBloke
- GPTQ 论文
- https://arxiv.org/abs/2210.1732