GPT-4o(“o”代表“omni”)旨在处理文本、音频和视频输入的组合,并可以生成文本、音频和图像格式的输出。
背景
在 GPT-4o 之前,用户可以使用语音模式与 ChatGPT 进行交互,该模式使用三个独立的模型运行。GPT-4o 将把这些功能集成到一个模型中,该模型在文本、视觉和音频方面进行了训练。这种统一的方法确保所有输入(无论是文本、视觉还是听觉)都由同一个神经网络进行连贯处理。
当前 API 功能
目前,API 仅支持输入,其输出模式与 .包括音频在内的其他模式将很快推出。本指南将帮助您开始使用 GPT-4o 进行文本、图像和视频理解。{text, image}{text}gpt-4-turbo
开始
安装适用于 Python 的 OpenAI 开发工具包
%pip install --upgrade openai --quiet配置 OpenAI 客户端并提交测试请求
要设置客户端供我们使用,我们需要创建一个 API 密钥来用于我们的请求。如果您已有可供使用的 API 密钥,请跳过这些步骤。
您可以按照以下步骤获取 API 密钥:
- 创建新项目
- 在项目中生成 API 密钥
- (推荐,但不是必需的)将所有项目的 API 密钥设置为环境变量
完成此设置后,让我们从第一个请求的模型的简单 {text} 输入开始。我们将同时使用 和 消息作为第一个请求,我们将收到来自角色的响应。systemuserassistant
from openai import OpenAI
import os
## Set the API key and model name
MODEL="gpt-4o"
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY", "<your OpenAI API key if not set as an env var>"))completion = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a helpful assistant. Help me with my math homework!"}, # <-- This is the system message that provides context to the model
{"role": "user", "content": "Hello! Could you solve 2+2?"} # <-- This is the user message for which the model will generate a response
]
)
print("Assistant: " + completion.choices[0].message.content)Assistant: Of course! \[ 2 + 2 = 4 \] If you have any other questions, feel free to ask!
图像处理
GPT-4o可以直接处理图像,并根据图像进行智能操作。我们可以提供两种格式的图像:
- Base64 编码
- 网址
让我们首先查看我们将使用的图像,然后尝试将此图像作为 Base64 和 API 的 URL 链接发送
from IPython.display import Image, display, Audio, Markdown
import base64
IMAGE_PATH = "data/triangle.png"
# Preview image for context
display(Image(IMAGE_PATH))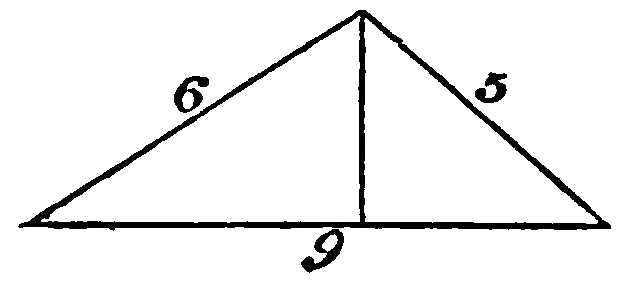
Base64 图像处理
# Open the image file and encode it as a base64 string
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
base64_image = encode_image(IMAGE_PATH)
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a helpful assistant that responds in Markdown. Help me with my math homework!"},
{"role": "user", "content": [
{"type": "text", "text": "What's the area of the triangle?"},
{"type": "image_url", "image_url": {
"url": f"data:image/png;base64,{base64_image}"}
}
]}
],
temperature=0.0,
)
print(response.choices[0].message.content)To find the area of the triangle, we can use Heron's formula. First, we need to find the semi-perimeter of the triangle.
The sides of the triangle are 6, 5, and 9.
1. Calculate the semi-perimeter \( s \):
\[ s = \frac{a + b + c}{2} = \frac{6 + 5 + 9}{2} = 10 \]
2. Use Heron's formula to find the area \( A \):
\[ A = \sqrt{s(s-a)(s-b)(s-c)} \]
Substitute the values:
\[ A = \sqrt{10(10-6)(10-5)(10-9)} \]
\[ A = \sqrt{10 \cdot 4 \cdot 5 \cdot 1} \]
\[ A = \sqrt{200} \]
\[ A = 10\sqrt{2} \]
So, the area of the triangle is \( 10\sqrt{2} \) square units.
URL图像处理
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a helpful assistant that responds in Markdown. Help me with my math homework!"},
{"role": "user", "content": [
{"type": "text", "text": "What's the area of the triangle?"},
{"type": "image_url", "image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/e/e2/The_Algebra_of_Mohammed_Ben_Musa_-_page_82b.png"}
}
]}
],
temperature=0.0,
)
print(response.choices[0].message.content)To find the area of the triangle, we can use Heron's formula. Heron's formula states that the area of a triangle with sides of length \(a\), \(b\), and \(c\) is:
\[ \text{Area} = \sqrt{s(s-a)(s-b)(s-c)} \]
where \(s\) is the semi-perimeter of the triangle:
\[ s = \frac{a + b + c}{2} \]
For the given triangle, the side lengths are \(a = 5\), \(b = 6\), and \(c = 9\).
First, calculate the semi-perimeter \(s\):
\[ s = \frac{5 + 6 + 9}{2} = \frac{20}{2} = 10 \]
Now, apply Heron's formula:
\[ \text{Area} = \sqrt{10(10-5)(10-6)(10-9)} \]
\[ \text{Area} = \sqrt{10 \cdot 5 \cdot 4 \cdot 1} \]
\[ \text{Area} = \sqrt{200} \]
\[ \text{Area} = 10\sqrt{2} \]
So, the area of the triangle is \(10\sqrt{2}\) square units.
视频处理
虽然无法直接将视频发送到 API,但如果您对帧进行采样,然后将它们作为图像提供,GPT-4o 可以理解视频。它在这方面的表现比 GPT-4 Turbo 更好。
由于 API 中的 GPT-4o 尚不支持音频输入(截至 2024 年 5 月),我们将结合使用 GPT-4o 和 Whisper 来处理所提供视频的音频和视频,并展示两个用例:
- 综述
- 问答
视频处理设置
我们将使用两个 python 包进行视频处理 - opencv-python 和 moviepy。
这些需要 ffmpeg,因此请务必事先安装。根据您的操作系统,您可能需要运行或brew install ffmpegsudo apt install ffmpeg
%pip install opencv-python --quiet
%pip install moviepy --quiet将视频处理成两个组件:帧和音频
import cv2
from moviepy.editor import VideoFileClip
import time
import base64
# We'll be using the OpenAI DevDay Keynote Recap video. You can review the video here: https://www.youtube.com/watch?v=h02ti0Bl6zk
VIDEO_PATH = "data/keynote_recap.mp4"def process_video(video_path, seconds_per_frame=2):
base64Frames = []
base_video_path, _ = os.path.splitext(video_path)
video = cv2.VideoCapture(video_path)
total_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
fps = video.get(cv2.CAP_PROP_FPS)
frames_to_skip = int(fps * seconds_per_frame)
curr_frame=0
# Loop through the video and extract frames at specified sampling rate
while curr_frame < total_frames - 1:
video.set(cv2.CAP_PROP_POS_FRAMES, curr_frame)
success, frame = video.read()
if not success:
break
_, buffer = cv2.imencode(".jpg", frame)
base64Frames.append(base64.b64encode(buffer).decode("utf-8"))
curr_frame += frames_to_skip
video.release()
# Extract audio from video
audio_path = f"{base_video_path}.mp3"
clip = VideoFileClip(video_path)
clip.audio.write_audiofile(audio_path, bitrate="32k")
clip.audio.close()
clip.close()
print(f"Extracted {len(base64Frames)} frames")
print(f"Extracted audio to {audio_path}")
return base64Frames, audio_path
# Extract 1 frame per second. You can adjust the `seconds_per_frame` parameter to change the sampling rate
base64Frames, audio_path = process_video(VIDEO_PATH, seconds_per_frame=1)
MoviePy - Writing audio in data/keynote_recap.mp3
MoviePy - Done. Extracted 218 frames Extracted audio to data/keynote_recap.mp3
## Display the frames and audio for context
display_handle = display(None, display_id=True)
for img in base64Frames:
display_handle.update(Image(data=base64.b64decode(img.encode("utf-8")), width=600))
time.sleep(0.025)
Audio(audio_path)
示例 1:摘要
现在我们已经有了视频帧和音频,让我们运行一些不同的测试来生成视频摘要,以比较使用不同模态的模型的结果。我们应该期望看到,使用来自视觉和音频输入的上下文生成的摘要将是最准确的,因为模型能够使用视频中的整个上下文。
- 视觉摘要
- 音频摘要
- 视觉 + 音频摘要
视觉摘要
通过仅向模型发送视频中的帧来生成视觉摘要。仅使用框架,模型可能会捕捉到视觉方面,但会错过演讲者讨论的任何细节。
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are generating a video summary. Please provide a summary of the video. Respond in Markdown."},
{"role": "user", "content": [
"These are the frames from the video.",
*map(lambda x: {"type": "image_url",
"image_url": {"url": f'data:image/jpg;base64,{x}', "detail": "low"}}, base64Frames)
],
}
],
temperature=0,
)
print(response.choices[0].message.content)## Video Summary: OpenAI DevDay Keynote Recap The video appears to be a keynote recap from OpenAI's DevDay event. Here are the key points covered in the video: 1. **Introduction and Event Overview**: - The video starts with the title "OpenAI DevDay" and transitions to "Keynote Recap." - The event venue is shown, with attendees gathering and the stage set up. 2. **Keynote Presentation**: - A speaker, presumably from OpenAI, takes the stage to present. - The presentation covers various topics related to OpenAI's latest developments and announcements. 3. **Announcements**: - **GPT-4 Turbo**: Introduction of GPT-4 Turbo, highlighting its enhanced capabilities and performance. - **JSON Mode**: A new feature that allows for structured data output in JSON format. - **Function Calling**: Demonstration of improved function calling capabilities, making interactions more efficient. - **Context Length and Control**: Enhancements in context length and user control over the model's responses. - **Better Knowledge Integration**: Improvements in the model's knowledge base and retrieval capabilities. 4. **Product Demonstrations**: - **DALL-E 3**: Introduction of DALL-E 3 for advanced image generation. - **Custom Models**: Announcement of custom models, allowing users to tailor models to specific needs. - **API Enhancements**: Updates to the API, including threading, retrieval, and code interpreter functionalities. 5. **Pricing and Token Efficiency**: - Discussion on GPT-4 Turbo pricing, emphasizing cost efficiency with reduced input and output tokens. 6. **New Features and Tools**: - Introduction of new tools and features for developers, including a variety of GPT-powered applications. - Emphasis on building with natural language and the ease of creating custom applications. 7. **Closing Remarks**: - The speaker concludes the presentation, thanking the audience and highlighting the future of OpenAI's developments. The video ends with the OpenAI logo and the event title "OpenAI DevDay."
结果符合预期 - 该模型能够捕获视频视觉效果的高级方面,但错过了语音中提供的细节。
音频摘要
音频摘要是通过向模型发送音频脚本来生成的。仅使用音频时,模型可能会偏向于音频内容,并且会错过演示和视觉对象提供的上下文。
{audio}GPT-4o 的输入目前不可用,但很快就会推出!现在,我们使用现有的模型来处理音频whisper-1
# Transcribe the audio
transcription = client.audio.transcriptions.create(
model="whisper-1",
file=open(audio_path, "rb"),
)
## OPTIONAL: Uncomment the line below to print the transcription
#print("Transcript: ", transcription.text + "\n\n")
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content":"""You are generating a transcript summary. Create a summary of the provided transcription. Respond in Markdown."""},
{"role": "user", "content": [
{"type": "text", "text": f"The audio transcription is: {transcription.text}"}
],
}
],
temperature=0,
)
print(response.choices[0].message.content)### Summary Welcome to OpenAI's first-ever Dev Day. Key announcements include: - **GPT-4 Turbo**: A new model supporting up to 128,000 tokens of context, featuring JSON mode for valid JSON responses, improved instruction following, and better knowledge retrieval from external documents or databases. It is also significantly cheaper than GPT-4. - **New Features**: - **Dolly 3**, **GPT-4 Turbo with Vision**, and a new **Text-to-Speech model** are now available in the API. - **Custom Models**: A program where OpenAI researchers help companies create custom models tailored to their specific use cases. - **Increased Rate Limits**: Doubling tokens per minute for established GPT-4 customers and allowing requests for further rate limit changes. - **GPTs**: Tailored versions of ChatGPT for specific purposes, programmable through conversation, with options for private or public sharing, and a forthcoming GPT Store. - **Assistance API**: Includes persistent threads, built-in retrieval, a code interpreter, and improved function calling. OpenAI is excited about the future of AI integration and looks forward to seeing what users will create with these new tools. The event concludes with an invitation to return next year for more advancements.
音频摘要偏向于演讲中讨论的内容,但结构比视频摘要少得多。
音频 + 视频摘要
音频 + 视频摘要是通过同时向模型发送视频中的视觉和音频来生成的。当发送这两个消息时,模型应该更好地总结,因为它可以一次感知整个视频。
## Generate a summary with visual and audio
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content":"""You are generating a video summary. Create a summary of the provided video and its transcript. Respond in Markdown"""},
{"role": "user", "content": [
"These are the frames from the video.",
*map(lambda x: {"type": "image_url",
"image_url": {"url": f'data:image/jpg;base64,{x}', "detail": "low"}}, base64Frames),
{"type": "text", "text": f"The audio transcription is: {transcription.text}"}
],
}
],
temperature=0,
)
print(response.choices[0].message.content)## Video Summary: OpenAI Dev Day ### Introduction - The video begins with the title "OpenAI Dev Day" and transitions to a keynote recap. ### Event Overview - The event is held at a venue with a sign reading "OpenAI Dev Day." - Attendees are seen entering and gathering in a large hall. ### Keynote Presentation - The keynote speaker introduces the event and announces the launch of GPT-4 Turbo. - **GPT-4 Turbo**: - Supports up to 128,000 tokens of context. - Introduces a new feature called JSON mode for valid JSON responses. - Improved function calling capabilities. - Enhanced instruction-following and knowledge retrieval from external documents or databases. - Knowledge updated up to April 2023. - Available in the API along with DALL-E 3, GPT-4 Turbo with Vision, and a new Text-to-Speech model. ### Custom Models - Launch of a new program called Custom Models. - Researchers will collaborate with companies to create custom models tailored to specific use cases. - Higher rate limits and the ability to request changes to rate limits and quotas directly in API settings. ### Pricing and Performance - **GPT-4 Turbo**: - 3x cheaper for prompt tokens and 2x cheaper for completion tokens compared to GPT-4. - Doubling the tokens per minute for established GPT-4 customers. ### Introduction of GPTs - **GPTs**: - Tailored versions of ChatGPT for specific purposes. - Combine instructions, expanded knowledge, and actions for better performance and control. - Can be created without coding, through conversation. - Options to make GPTs private, share publicly, or create for company use in ChatGPT Enterprise. - Announcement of the upcoming GPT Store. ### Assistance API - **Assistance API**: - Includes persistent threads for handling long conversation history. - Built-in retrieval and code interpreter with a working Python interpreter in a sandbox environment. - Improved function calling. ### Conclusion - The speaker emphasizes the potential of integrating intelligence everywhere, providing "superpowers on demand." - Encourages attendees to return next year, hinting at even more advanced developments. - The event concludes with thanks to the attendees. ### Closing - The video ends with the OpenAI logo and a final thank you message.
在结合视频和音频后,我们能够获得更详细和全面的事件摘要,该摘要使用了视频中的视觉和音频元素的信息。
示例 2:问答
对于问答,我们将使用与之前相同的概念来询问处理后的视频问题,同时运行相同的 3 个测试,以演示组合输入模式的好处:
- 视觉问答
- 音频问答
- 视觉 + 音频问答
QUESTION = "Question: Why did Sam Altman have an example about raising windows and turning the radio on?"qa_visual_response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": "Use the video to answer the provided question. Respond in Markdown."},
{"role": "user", "content": [
"These are the frames from the video.",
*map(lambda x: {"type": "image_url", "image_url": {"url": f'data:image/jpg;base64,{x}', "detail": "low"}}, base64Frames),
QUESTION
],
}
],
temperature=0,
)
print("Visual QA:\n" + qa_visual_response.choices[0].message.content)Visual QA: Sam Altman used the example about raising windows and turning the radio on to demonstrate the function calling capability of GPT-4 Turbo. The example illustrated how the model can interpret and execute multiple commands in a more structured and efficient manner. The "before" and "after" comparison showed how the model can now directly call functions like `raise_windows()` and `radio_on()` based on natural language instructions, showcasing improved control and functionality.
qa_audio_response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content":"""Use the transcription to answer the provided question. Respond in Markdown."""},
{"role": "user", "content": f"The audio transcription is: {transcription.text}. \n\n {QUESTION}"},
],
temperature=0,
)
print("Audio QA:\n" + qa_audio_response.choices[0].message.content)Audio QA: The provided transcription does not include any mention of Sam Altman or an example about raising windows and turning the radio on. Therefore, I cannot provide an answer based on the given transcription.
qa_both_response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content":"""Use the video and transcription to answer the provided question."""},
{"role": "user", "content": [
"These are the frames from the video.",
*map(lambda x: {"type": "image_url",
"image_url": {"url": f'data:image/jpg;base64,{x}', "detail": "low"}}, base64Frames),
{"type": "text", "text": f"The audio transcription is: {transcription.text}"},
QUESTION
],
}
],
temperature=0,
)
print("Both QA:\n" + qa_both_response.choices[0].message.content)Both QA: Sam Altman used the example of raising windows and turning the radio on to demonstrate the improved function calling capabilities of GPT-4 Turbo. The example illustrated how the model can now handle multiple function calls more effectively and follow instructions better. In the "before" scenario, the model had to be prompted separately for each action, whereas in the "after" scenario, the model could handle both actions in a single prompt, showcasing its enhanced ability to manage and execute multiple tasks simultaneously.
比较这三个答案,最准确的答案是通过使用视频中的音频和视频生成的。Sam Altman在主题演讲中没有讨论升起的窗户或收音机,但提到了该模型在单个请求中执行多个功能的改进功能,而示例则在他身后显示。
结论
集成许多输入模式(如音频、视觉和文本)可显著提高模型在各种任务上的性能。这种多模态方法可以更全面地理解和互动,更密切地反映人类感知和处理信息的方式。
目前,API 中的 GPT-4o 支持文本和图像输入,音频功能即将推出。