FastChat 是一个开放平台,用于训练、服务和评估基于大型语言模型的聊天机器人。
核心功能包括:
最先进模型(例如,Vicuna、FastChat-T5)的权重、训练代码和评估代码。
具有 Web UI 和 OpenAI 兼容 RESTful API 的分布式多模型服务系统。
https://github.com/lm-sys/FastChat
下载 Conda 安装脚本,
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
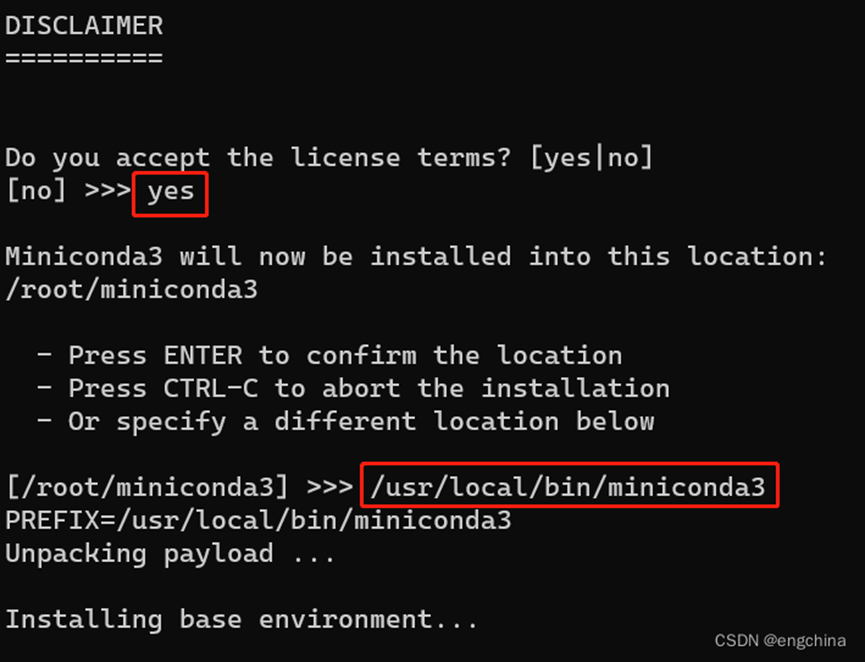
运行安装脚本,
bash Miniconda3-latest-Linux-x86_64.sh
按提示操作。当提示是否初始化 Conda 时,输入 “yes”,
安装完成后,关闭当前终端并打开新终端,这将激活 Conda,
sudo su - root
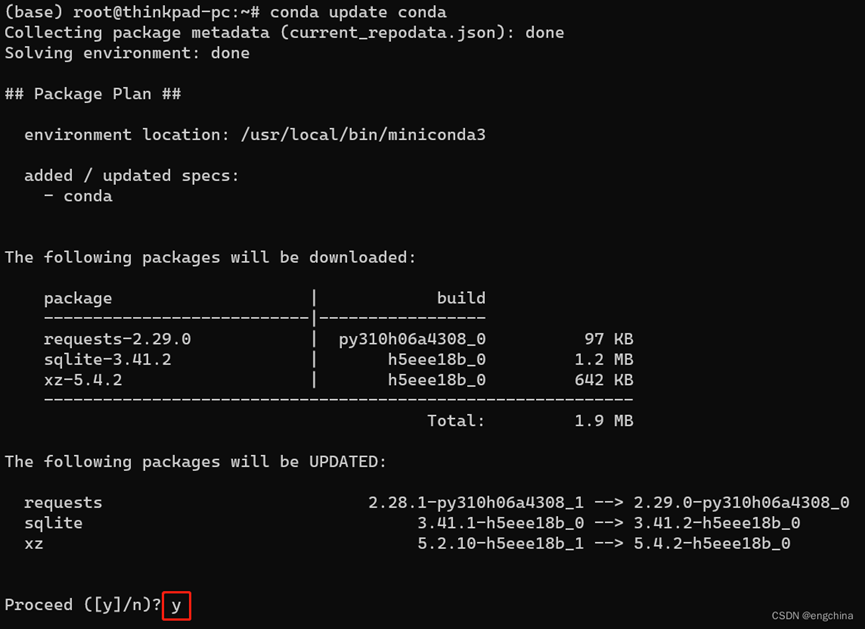
更新 Conda 至最新版本,
conda update conda

conda create -n fastchat python==3.10.6
conda activate fastchat
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
克隆代码,
git clone --recursive https://github.com/lm-sys/FastChat.git; cd FastChat
升级 pip
pip3 install --upgrade pip
安装依赖库,
pip3 install -e .
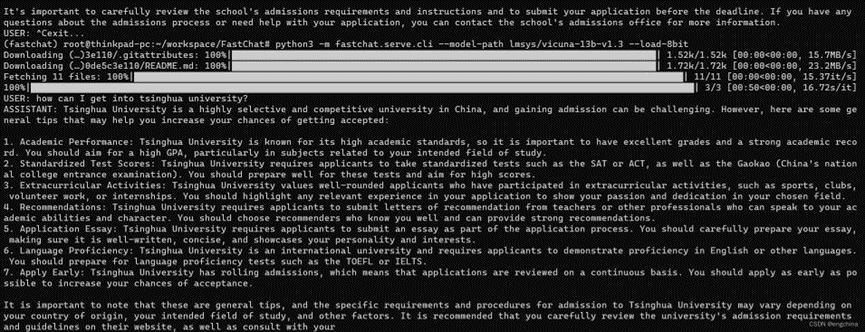
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-13b-v1.3 --load-8bit

启动 controller,
python3 -m fastchat.serve.controller
启动 worker,
python3 -m fastchat.serve.model_worker --model-path lmsys/vicuna-7b-v1.3
启动 Gradio Web 服务器,
python3 -m fastchat.serve.gradio_web_server
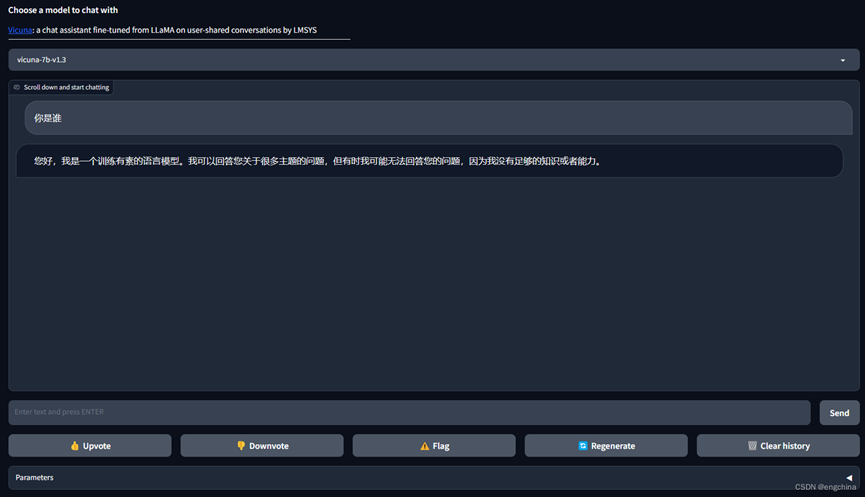
浏览器打开 http://127.0.0.1:7860/?__theme=dark 进行访问,
安装依赖库,
pip install deepspeed
pip install git+https://github.com/huggingface/peft
下载数据 HealthCareMagic-100k.json,将数据存储在 ./data 目录下。
转换数据格式,
python3 -m fastchat.data.convert_alpaca --in-file ./data/HealthCareMagic-100k.json --out-file ./data/HealthCareMagic-100k-Lora.json
开始微调,
CUDA_VISIBLE_DEVICES=0 \
deepspeed --num_gpus=1 fastchat/train/train_lora.py \
--model_name_or_path lmsys/vicuna-7b-v1.3 \
--lora_r 8 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--data_path ./data/HealthCareMagic-100k-Lora.json \
--bf16 True \
--output_dir ./checkpoints \
--num_train_epochs 3 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 1 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 1200 \
--save_total_limit 100 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--tf32 True \
--model_max_length 2048 \
--q_lora True \
--deepspeed playground/deepspeed_config_s2.json \
未完待续!
pip install einops flash_attn==1.0.5
完结!