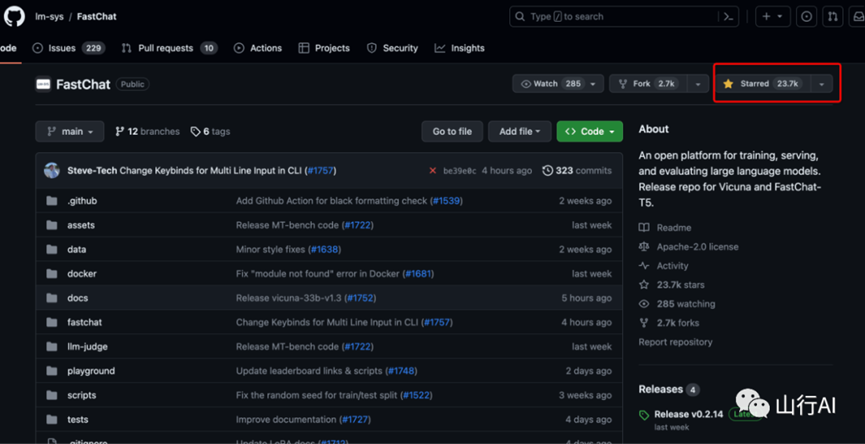
在AI盛起的当下,各类AI应用不断地出现在人们的视野中,AI正在重塑着各行各业。相信现在各大公司都在进行着不同程度的AI布局,有AI大模型自研能力的公司毕竟是少数,对于大部分公司来说,在一款开源可商用的大模型基础上进行行业数据微调也正在成为一种不错的选择。
FastChat是开源大模型列表中的一员(详见文章:open-llms 开源可商用的优秀大模型资源库),FastChat是一个用于训练、部署和评估基于大型语言模型的聊天机器人的开放平台。其核心功能包括:
•最先进模型的权重、训练代码和评估代码(例如Vicuna、FastChat-T5)。•基于分布式多模型的服务系统,具有Web界面和与OpenAI兼容的RESTful API。
体验地址为:https://chat.lmsys.org/
与开源的大模型聊天:
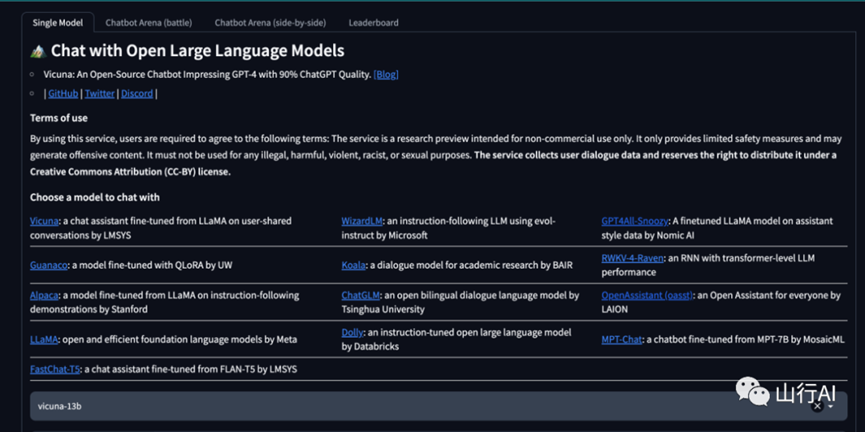
可选模型有:
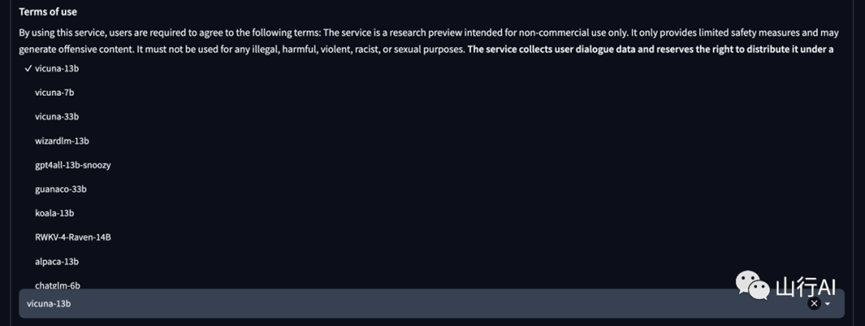
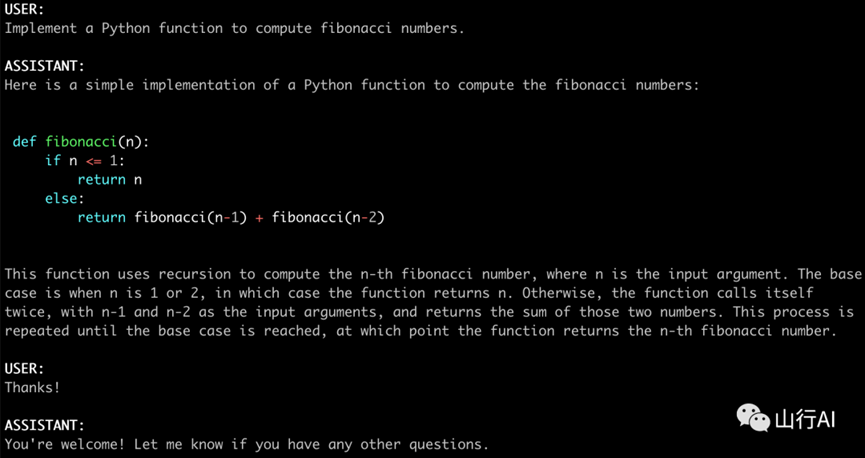
体验效果:
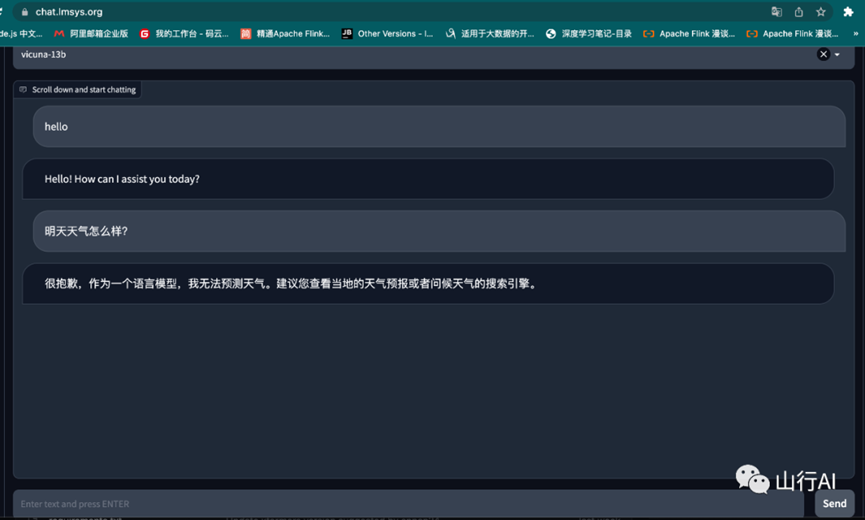
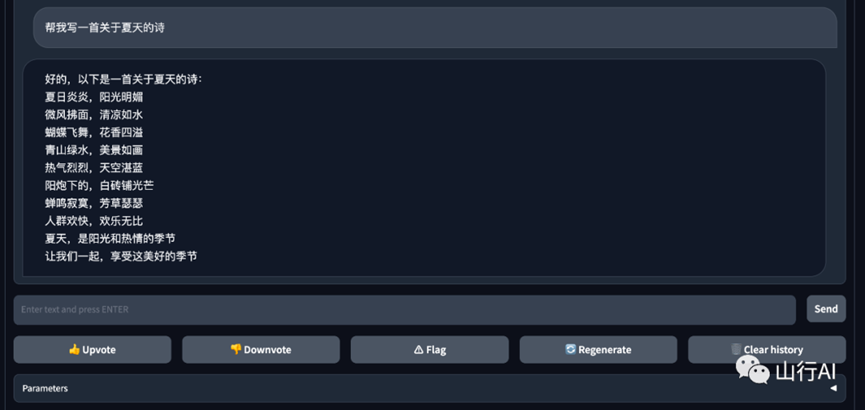
可以看出vicuna-13B模型的中文效果还是可以的。
| 演示 [1] | Arena [2] | Discord [3] | Twitter [4] |
FastChat是一个用于训练、部署和评估基于大型语言模型的聊天机器人的开放平台。其核心功能包括:
•最先进模型的权重、训练代码和评估代码(例如Vicuna、FastChat-T5)。•基于分布式多模型的服务系统,具有Web界面和与OpenAI兼容的RESTful API。
•[2023/05] 🔥 我们推出了 Chatbot Arena ,用于大型语言模型之间的对战。请查看博客文章[5]和演示[6]。•[2023/04] 我们发布了与商业使用兼容的 FastChat-T5 。请查看权重[7]和演示[8]。•[2023/03] 我们发布了 Vicuna:一款开源聊天机器人,与ChatGPT质量相当达到GPT-4的90% 。请查看博客文章[9]和演示[10]。
•安装[11]•模型权重[12]•使用命令行界面进行推理[13]•使用Web界面进行服务[14]•API[15]•评估[16]•微调[17]•引用[18]
*
pip3 install fschat
1.克隆此代码库并进入FastChat文件夹
git clone https://github.com/lm-sys/FastChat.git
cd FastChat
如果你在Mac上运行:
*
brew install rust cmake
2.安装包
pip3 install --upgrade pip # 启用PEP 660支持
pip3 install -e .
我们发布了合并权重的Vicuna[19] v1.3版本。您不需要应用增量。 Vicuna基于LLaMA模型,请在LLaMA的模型许可证[20]下使用。
您可以使用下面的命令开始聊天。它将自动从Hugging Face的仓库中下载权重。 在下面的"使用命令行界面进行推理"部分中,可以查看更多命令选项和如何处理内存不足的情况。
|
大小 |
聊天命令 |
Hugging Face 仓库 |
|
7B |
|
lmsys/vicuna-7b-v1.3[21] |
|
13B |
|
lmsys/vicuna-13b-v1.3[22] |
|
33B |
|
lmsys/vicuna-33b-v1.3[23] |
旧权重 : 请参阅 docs/vicuna_weights_version.md[24] 查看所有权重版本及其差异。
服务端架构图:
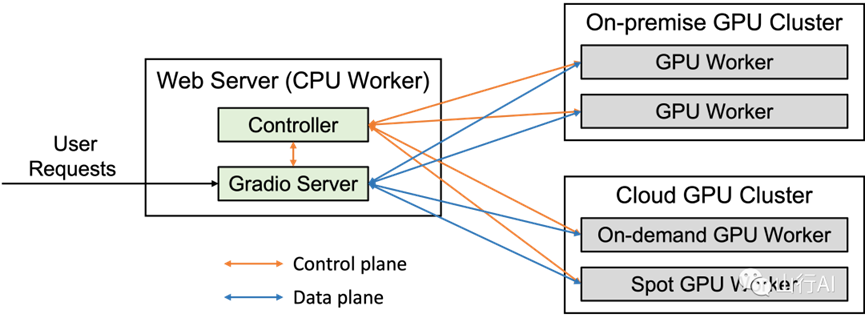
server arch
只需运行以下命令开始聊天。 它将自动从 Hugging Face 的 repo[25] 下载权重。
*
python3 -m fastchat.serve.cli --model-path lmsys/fastchat-t5-3b-v1.0
(实验性功能:您可以使用 --style rich 来启用富文本输出,提高某些非 ASCII 内容的文本流传输质量。在某些终端上可能无法正常工作。)
FastChat支持多种模型,包括Vicuna、Alpaca、Baize、ChatGLM、Dolly、Falcon、FastChat-T5、GPT4ALL、Guanaco、MTP、OpenAssistant、RedPajama、StableLM、WizardLM等等。
请在此处[26]查看完整的支持模型列表和添加新模型的说明。
下面的命令对于Vicuna-7B需要大约14GB的GPU内存,对于Vicuna-13B需要28GB的GPU内存。 如果您的内存不足,请参考下面的"内存不足"部分。 --model-path 可以是本地文件夹或Hugging Face的repo名称。
*
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.3
您可以使用模型并行ism从同一台机器上的多个GPU中聚合GPU内存。
*
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.3 --num-gpus 2
这在仅使用CPU时运行,不需要GPU。对于Vicuna-7B,它需要大约30GB的CPU内存,对于Vicuna-13B,它需要大约60GB的CPU内存。
*
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.3 --device cpu
使用 --device mps 在Mac电脑上启用GPU加速(需要 torch >= 2.0)。 使用 --load-8bit 打开8位压缩。
*
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.3 --device mps --load-8bit
Vicuna-7B可以在32GB的M1 MacBook上每秒处理1-2个词。
安装Intel Extension for PyTorch[27]。设置OneAPI环境变量:
*
source /opt/intel/oneapi/setvars.sh
使用 --device xpu 启用XPU/GPU加速。
*
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.3 --device xpu
Vicuna-7B 可以在Intel Arc A770 16GB上运行。
如果内存不足,您可以通过在上述命令中添加 --load-8bit 来启用8位压缩。 这可以将内存使用量减少约一半,但会略微降低模型质量。 它与CPU、GPU和Metal后端兼容。 带有8位压缩的Vicuna-13B可以在单个NVIDIA 3090/4080/T4/V100(16GB)GPU上运行。
*
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.3 --load-8bit
除此之外,您还可以在上述命令中添加 --cpu- offloading,将不适合您的GPU的权重卸载到CPU内存中。这需要启用8位压缩,并安装bitsandbytes包,该包仅在Linux操作系统上可用。
•FastChat支持使用GPTQ-for-LLaMa[28]进行GPTQ 4位推理。请参阅docs/gptq.md[29]。•MLC LLM[30]由TVM Unity[31]编译器支持,通过Vulkan、Metal、CUDA和WebGPU在手机、消费级GPU和Web浏览器上原生部署Vicuna。
要使用Web UI进行服务,您需要三个主要组件:与用户交互的Web服务器、托管一个或多个模型的模型工作者,以及协调Web服务器和模型工作者的控制器。您可以在此处[32]了解更多关于架构的信息。
以下是在终端中执行的命令:
*
python3 -m fastchat.serve.controller
该控制器管理分布式工作者。
*
python3 -m fastchat.serve.model_worker --model-path lmsys/vicuna-7b-v1.3
等待进程完成加载模型并显示 "Uvicorn running on ..."。模型工作者将向控制器注册自己。
为确保您的模型工作者已正确连接到控制器,请使用以下命令发送测试消息:
*
python3 -m fastchat.serve.test_message --model-name vicuna-7b-v1.3
您将看到一个简短的输出。
*
python3 -m fastchat.serve.gradio_web_server
这是用户将与之交互的用户界面。
按照这些步骤,您将能够使用Web UI提供您的模型。您可以打开浏览器并与模型聊天。如果模型没有显示出来,请尝试重新启动Gradio Web服务器。
•您可以将多个模型工作者注册到单个控制器,这可用于提高单个模型的吞吐量或同时提供多个模型。在这样做时,请为不同的模型工作者分配不同的GPU和端口。
# worker 0
CUDA_VISIBLE_DEVICES=0 python3 -m fastchat.serve.model_worker --model-path lmsys/vicuna-7b-v1.3 --controller http://localhost:21001 --port 31000 --worker http://localhost:31000
# worker 1
CUDA_VISIBLE_DEVICES=1 python3 -m fastchat.serve.model_worker --model-path lmsys/fastchat-t5-3b-v1.0 --controller http://localhost:21001 --port 31001 --worker http://localhost:31001
•您还可以启动一个包含Chatbot Arena选项卡的多标签Gradio服务器。
*
python3 -m fastchat.serve.gradio_web_server_multi
FastChat为其支持的模型提供了兼容OpenAI的API,因此您可以将FastChat作为OpenAI API的本地替代品使用。 FastChat服务器与openai-python[33]库和cURL命令兼容。 请参阅docs/openai_api.md[34]。
请参阅 fastchat/serve/huggingface_api.py。
请参阅 docs/langchain_integration[35]。
我们的AI增强评估流程基于GPT-4。本部分提供了流程的高级概述。详细的说明,请参阅 evaluation[36] 文档。
1.从不同的模型生成回答:使用 qa_baseline_gpt35.py 获取ChatGPT的回答,或者指定模型检查点并运行 get_model_answer.py 获取 Vicuna 和其他模型的回答。2.使用 GPT-4 生成评论:使用 GPT-4 自动生成评论。如果您无法使用 GPT-4 API,则可以手动执行此步骤。3.生成可视化数据:运行 generate_webpage_data_from_table.py 生成静态网站的数据,以便您可以可视化评估数据。4.可视化数据:在 webpage 目录下提供一个静态网站。您可以使用 python3 -m http.server 在本地提供网站服务。
我们在评估中使用了一种使用 JSON Lines 编码的数据格式。该格式包括有关模型、提示、评论者、问题、回答和评论的信息。
您可以通过访问相关的 数据[37] 来自定义评估过程或为我们的项目做出贡献。
有关详细说明,请参阅 evaluation[38] 文档。
Vicuna 是通过使用从 ShareGPT.com 上收集的约 7 万个用户共享对话使用 LLaMA 基础模型进行微调而创建的,使用了公共的 API。为了确保数据质量,我们将 HTML 转换回 Markdown,并过滤掉一些不适当或低质量的样本。此外,我们将较长的对话分割成适合模型最大上下文长度的较小段落。有关清理 ShareGPT 数据的详细说明,请查看此处[39]。
由于一些考虑,我们目前可能不会发布 ShareGPT 数据集。如果您想尝试微调代码,您可以使用 dummy_conversation.json[40] 中的一些虚拟对话来运行它。您可以按照相同的格式插入自己的数据。
我们的代码基于Stanford Alpaca[41],并增加了对多轮对话的支持。 我们使用与 Stanford Alpaca 类似的超参数。
|
超参数 |
全局批大小 |
学习率 |
训练轮数 |
最大长度 |
权重衰减 |
|
Vicuna-13B |
128 |
2e-5 |
3 |
2048 |
0 |
您可以使用以下命令使用 4 个 A100 (40GB) 对 Vicuna-7B 进行训练。
torchrun --nproc_per_node=4 --master_port=20001 fastchat/train/train_mem.py \
--model_name_or_path ~/model_weights/llama-7b \
--data_path data/dummy_conversation.json \
--bf16 True \
--output_dir output_vicuna \
--num_train_epochs 3 \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 2 \
--gradient_accumulation_steps 16 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 1200 \
--save_total_limit 10 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--fsdp "full_shard auto_wrap" \
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \
--tf32 True \
--model_max_length 2048 \
--gradient_checkpointing True \
--lazy_preprocess True
如果在模型保存过程中遇到内存不足的问题,请参考这里[42]的解决方案。
您可以使用以下命令使用 4 个 A100 (40GB) 对 FastChat-T5 进行训练。
torchrun --nproc_per_node=4 --master_port=9778 fastchat/train/train_flant5.py \
--model_name_or_path google/flan-t5-xl \
--data_path /data/dummy.json \
--bf16 True \
--output_dir ./checkpoints_flant5_3b \
--num_train_epochs 3 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 4 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 300 \
--save_total_limit 1 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--fsdp "full_shard auto_wrap" \
--fsdp_transformer_layer_cls_to_wrap T5Block \
--tf32 True \
--model_max_length 2048 \
--preprocessed_path ./preprocessed_data/processed.json \
--gradient_checkpointing True
您可以使用以下命令使用 QLoRA 和 ZeRO2 对 Vicuna-7B 进行微调。请注意,目前 QLoRA 不支持 ZeRO3,但 ZeRO3 支持 LoRA,其参考配置在 playground/deepspeed_config_s3.json 中。
deepspeed train_lora.py \
--model_name_or_path ~/model_weights/llama-7b \
--lora_r 8 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--data_path <path-to-data> \
--bf16 True \
--output_dir ./checkpoints \
--num_train_epochs 3 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 1 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 1200 \
--save_total_limit 100 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--tf32 True \
--model_max_length 2048 \
--q_lora True \
--deepspeed playground/deepspeed_config_s2.json \
在训练完成后,请使用我们的后处理函数(链接[43])更新保存的模型权重。更多讨论可以在这里[44]找到。
Skypilot[45] 是由加州大学伯克利分校开发的一个框架,用于在任何云平台(AWS、GCP、Azure、Lambda 等)上轻松且高效地运行机器学习工作负载。 在这里[46]找到使用托管的抢占式实例进行 Vicuna 微调并节省云成本的 SkyPilot 文档。
本仓库中的代码(训练、服务和评估)大部分是为以下论文开发或衍生出来的,请在引用时进行引用。
@misc{zheng2023judging,
title={Judging LLM-as-a-judge with MT-Bench and Chatbot Arena},
author={Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric. P Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica},
year={2023},
eprint={2306.05685},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
我们还计划将更多研究添加到本仓库中。
本文翻译整理自:GitHub - lm-sys/FastChat: An open platform for training, serving, and evaluating large language models. Release repo for Vicuna and FastChat-T5.[47]
FastChat是一个目前拥有23.7k star的项目,本文内容后续也会持续更新,喜欢的同学请点赞收藏。
[1] 演示 : https://chat.lmsys.org/[2] Arena : https://arena.lmsys.org[3] Discord : https://discord.gg/HSWAKCrnFx[4] Twitter : https://twitter.com/lmsysorg[5] 文章: https://lmsys.org/blog/2023-05-03-arena[6] 演示: https://arena.lmsys.org[7] 权重: #fastchat-t5[8] 演示: https://chat.lmsys.org[9] 文章: https://vicuna.lmsys.org[10] 演示: https://chat.lmsys.org[11] 安装: #安装[12] 模型权重: #模型权重[13] 使用命令行界面进行推理: #使用命令行界面进行推理[14] 使用Web界面进行服务: #使用Web界面进行服务[15] API: #API[16] 评估: #评估[17] 微调: #微调[18] 引用: #引用[19] Vicuna: https://lmsys.org/blog/2023-03-30-vicuna/[20] 模型许可证: https://github.com/facebookresearch/llama/blob/main/MODEL\_CARD.md[21] lmsys/vicuna-7b-v1.3: https://huggingface.co/lmsys/vicuna-7b-v1.3[22] lmsys/vicuna-13b-v1.3: https://huggingface.co/lmsys/vicuna-13b-v1.3[23] lmsys/vicuna-33b-v1.3: https://huggingface.co/lmsys/vicuna-33b-v1.3[24] docs/vicuna_weights_version.md: https://github.com/lm- sys/FastChat/blob/main/docs/vicuna_weights_version.md[25] repo: https://huggingface.co/lmsys/fastchat-t5-3b-v1.0[26] 此处: https://github.com/lm- sys/FastChat/blob/main/docs/model_support.md[27] Intel Extension for PyTorch: https://intel.github.io/intel-extension- for-pytorch/xpu/latest/tutorials/installation.html[28] GPTQ-for-LLaMa: https://github.com/qwopqwop200/GPTQ-for-LLaMa[29] docs/gptq.md: https://github.com/lm- sys/FastChat/blob/main/docs/gptq.md[30] MLC LLM: https://mlc.ai/mlc-llm/[31] TVM Unity: https://github.com/apache/tvm/tree/unity[32] 此处: https://github.com/lm- sys/FastChat/blob/main/docs/server_arch.md[33] openai-python: https://github.com/openai/openai-python[34] docs/openai_api.md: https://github.com/lm- sys/FastChat/blob/main/docs/openai_api.md[35] docs/langchain_integration: https://github.com/lm- sys/FastChat/blob/main/docs/langchain_integration.md[36] evaluation: fastchat/eval[37] 数据: fastchat/eval/table/[38] evaluation: fastchat/eval[39] 此处: https://github.com/lm- sys/FastChat/blob/main/docs/commands/data_cleaning.md[40] dummy_conversation.json: data/dummy_conversation.json[41] Stanford Alpaca: https://github.com/tatsu-lab/stanford\_alpaca[42] 这里: https://github.com/pytorch/pytorch/issues/98823[43] 链接: https://github.com/lm- sys/FastChat/blob/55051ad0f23fef5eeecbda14a2e3e128ffcb2a98/fastchat/utils.py#L166-L185[44] 这里: https://github.com/lm-sys/FastChat/issues/643[45] Skypilot: https://github.com/skypilot-org/skypilot[46] 这里: https://github.com/skypilot-org/skypilot/tree/master/llm/vicuna[47] GitHub - lm-sys/FastChat: An open platform for training, serving, and evaluating large language models. Release repo for Vicuna and FastChat-T5.: https://github.com/lm-sys/FastChat\#FastChat-T5