经过一段时间的准备,相关的硬件到货并调试完成,五一假期正好踏实干了3天,终于得到了一些有用的东西,在这里记录一下,为后续继续开展打个基础。
模型选择清华系的ChatGLM-6b,最早适合单机的模型,也是最近一直在研究的。
硬件部分:通常参考炼丹机的配置,正好后头有一台超微双U的工作站,从顺义扛回来作为框架。
cpu选择老E5-2680v2*2 内存64G 超微X9DAI主板,支持三卡。
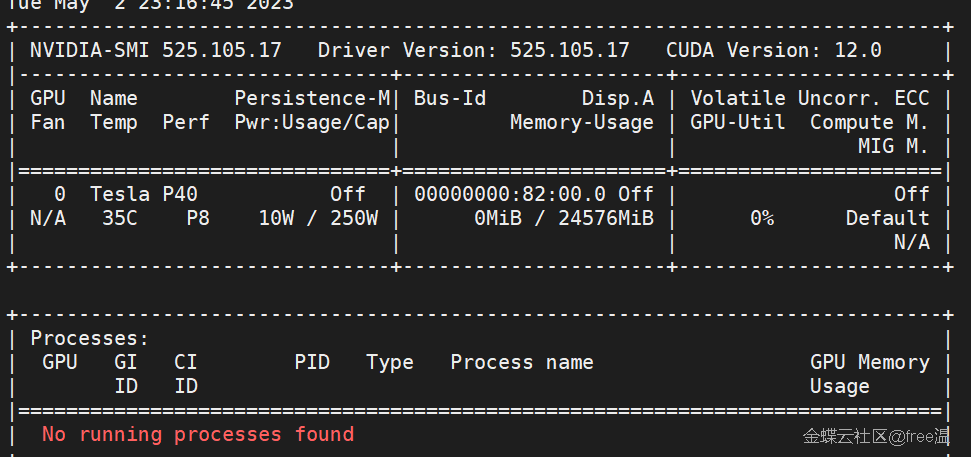
显卡选择p40 24G显存,因为电源不够强先上一块跑一下基础测试,单卡理论性能等同2080ti,就是需要改造风扇。后续电源换1kw,至少双卡部署。
硬盘必须是ssd,所以上了三星的ssd256G,sata接口,节省pci通道。后续可以继续换nvme
操作系统经过windows测试后,还是选择了乌班图最新的server版本。
安装系统无需多说,最麻烦的是安装显卡驱动,因为是双卡,而且GPU没有显卡输出,必须找个显卡做输出用,就弄了个最省电亮机卡配合使用。
先一套操作安装好驱动
然后安装chatglm-6b
# 新建chatglm环境
conda create -n chatglm python==3.10
# 激活chatglm环境
conda activate chatglm
# 安装PyTorch环境(根据自己的cuda版本选择合适的torch版本)
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
# 安装运行依赖
pip install -r requirement.txt
配置完成后跑一下demo没问题,就开始微调
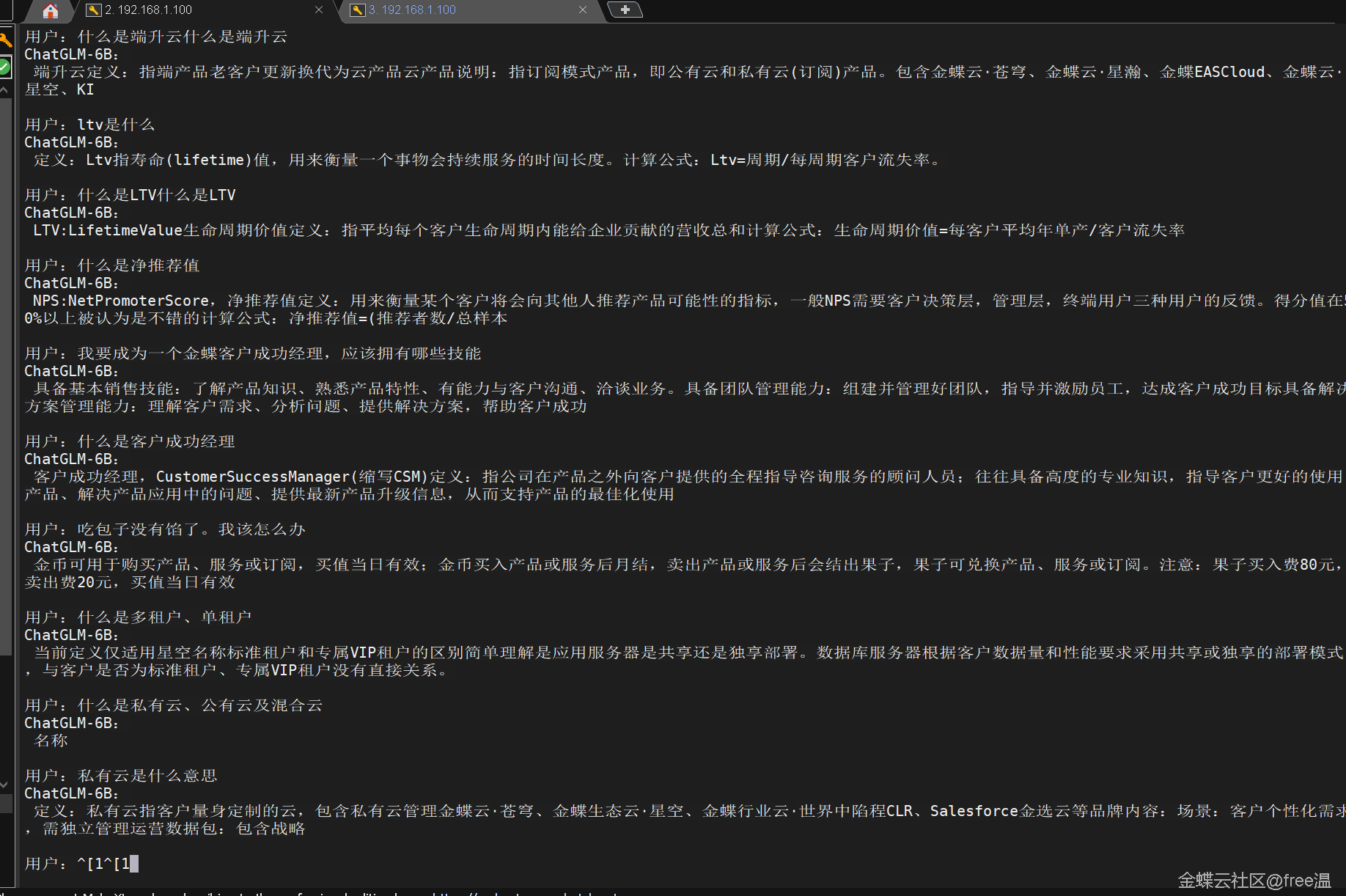
首先准备了客户成功百问百答数据集,作为测试。
。。。。。省略2天文字(还是比较折腾的,暂时不细写了,整理后单独发)
五月二日开始正式跑微调,先从简单的客户成功白问白答开始
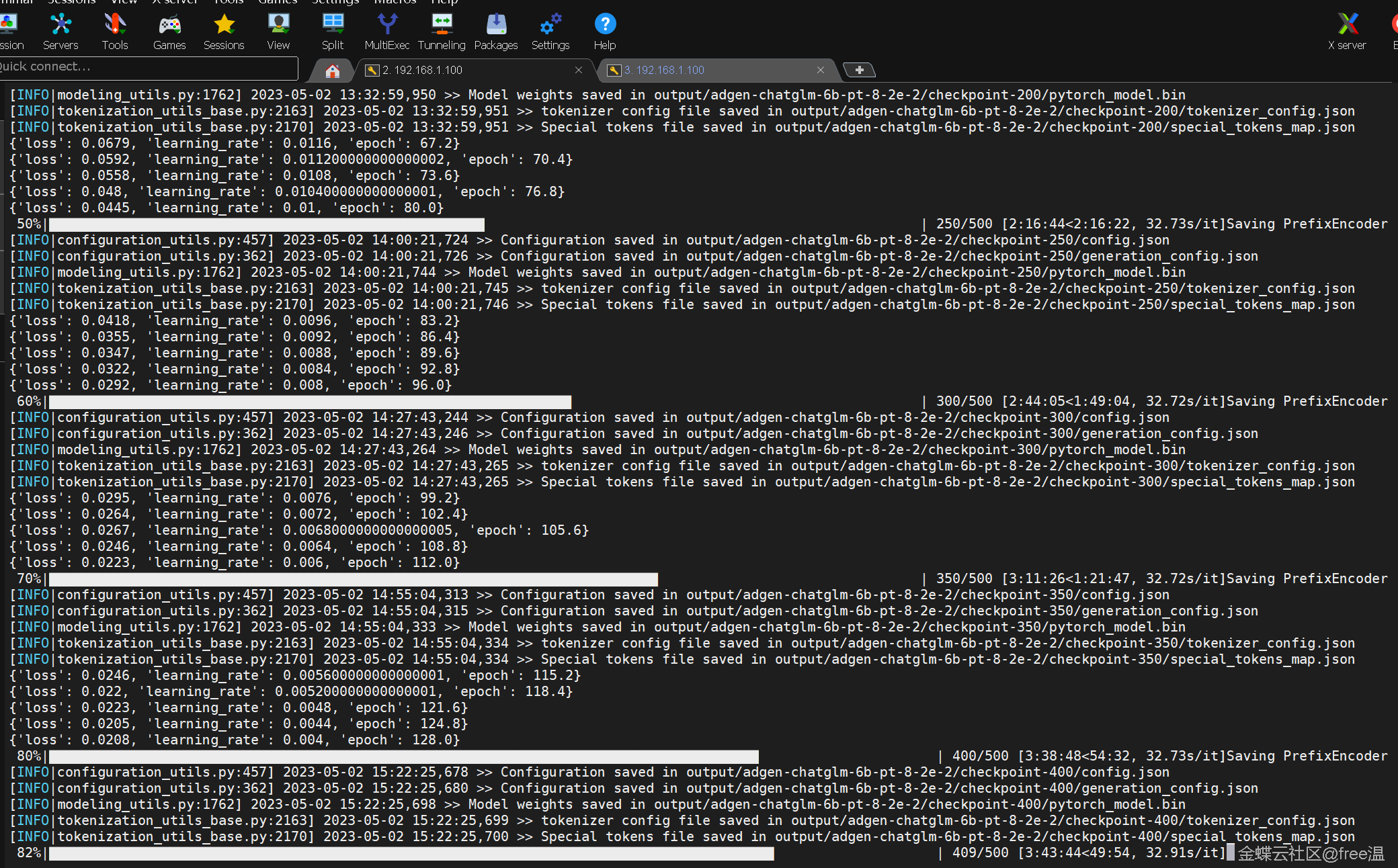
4个多小时训练完成,共计100个问答题。
跑完做了验证和测试,最后部署看下效果,基本达到预期效果(胡说八道还是偶尔会出现,正常)。
问答题的答复长度目前只做到500.正式训练的时候会放到2000,层数也只有64正式训练会到256.预计正式训练的时间会到2000分钟左右也就是40小时左右。双卡能到20小时
当前机器600w功率。跑一次模型还算能承受。
后面就是全面开始收集资料整理数据集的活,类似gpt刚开始找的30来个外包工人的活,我觉得我还没人家专业,先试试做个大一些的数据集,期待后续试验成果。
作者:free温
来源:金蝶云社区
原文链接:https://developer.kingdee.com/article/441382198638208000?productLineId=29
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。