Wan 2.2 by Alibaba Wan AI
主要功能
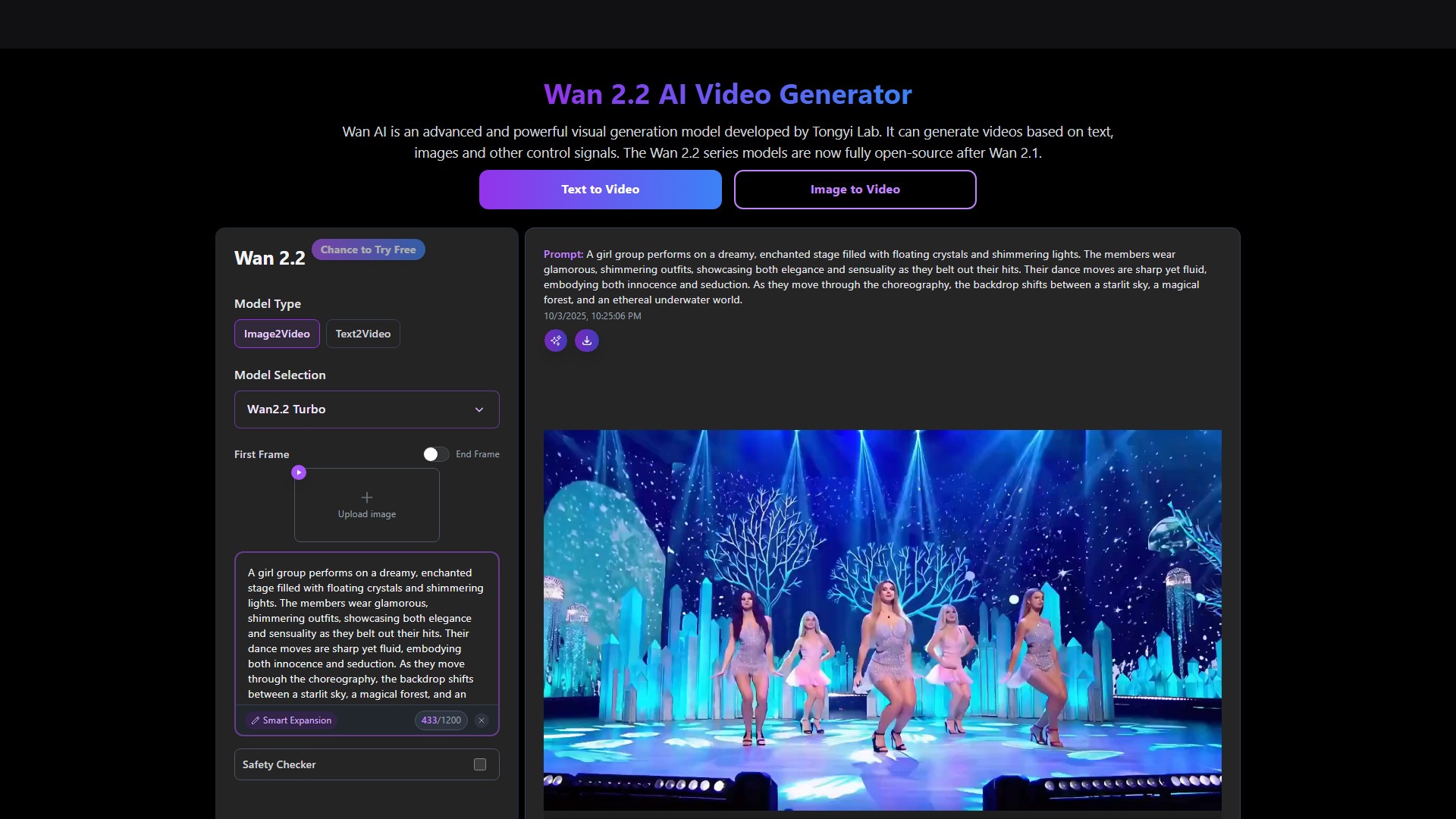
- 文本到视频(Text to Video):基于文本描述生成高质量视频
- 图像到视频(Image to Video):将静态图像转换为动态视频
- 首尾帧控制:支持指定起始帧和结束帧生成中间过渡
- 高级控制功能:提供精确的视频生成控制和创意选项
- 角色参考与动作参考:结合角色风格和参考动作创建个性化视频内容
技术特点
- SOTA性能:在多个基准测试中超越现有开源模型和商业解决方案
- 消费级GPU支持:T2V-1.3B模型仅需8.19GB显存,兼容几乎所有消费级GPU
- 多任务能力:在文本到视频、图像到视频、视频编辑、文本到图像和视频到音频等任务上表现优异
- 视觉文本生成:首个能够生成中英文文本的视频模型
- 强大的视频VAE:Wan-VAE提供卓越的效率和性能,能够编码和解码任意长度的1080P视频
模型版本
- Wan2.2-I2V:14B参数模型,支持480P和720P分辨率
- Wan2.2-T2V:14B参数模型,支持480P和720P分辨率
- Wan2.2-T2V-1.3B:轻量级版本,适合消费级GPU
- Wan2.2-FLF2V-14B-720P:首尾帧到视频生成模型
典型应用场景
- 复杂动作生成:擅长生成包含大量身体动作、复杂旋转、动态场景转换和流畅相机运动的逼真视频
- 物理模拟:生成准确模拟现实世界物理和真实物体交互的视频
- 电影级质量:提供电影般的视觉效果,具有丰富的纹理和多种风格化效果
- 可控编辑:具有通用编辑模型,可使用图像或视频参考进行精确编辑
使用说明
用户可以通过网页界面输入文本描述或上传图像来生成视频,支持智能扩展和安全检查功能。生成一个5秒480P视频需要130 credits,在RTX 4090上约需4分钟。
目标用户
专业内容创作者、视频制作人员、设计师、开发者和企业用户,以及希望尝试AI视频生成的普通用户。
核心优势
- 开源可用,降低使用门槛
- 支持消费级硬件,便于广泛部署
- 多功能集成,一模型多用途
- 高质量输出,媲美商业解决方案
- 中英文文本支持,应用场景广泛
计价模式:
Freemium
Paid
评论