从ChatGPT出圈也快一年了,中文大模型也是一个百花齐放的态势, 如果你现在问我中文大语言模型及相关生态发展到了什么地步了。我想上面那段北岛的诗句就是一个很好的《回答》。
中文LLM生态观察
模型
就开源的部分而言,从一开始的MOSS[1] ChatGLM[2] ChatGLM2 [3] 到后来的 baichan [4] 基于LLama2 微调的 中文LLama2 [5] 再到最近开源的 通义千问 Qwen [6] 。 至于更多模型和相关评分榜单可以看一直在维护更新模型汇总的文章。
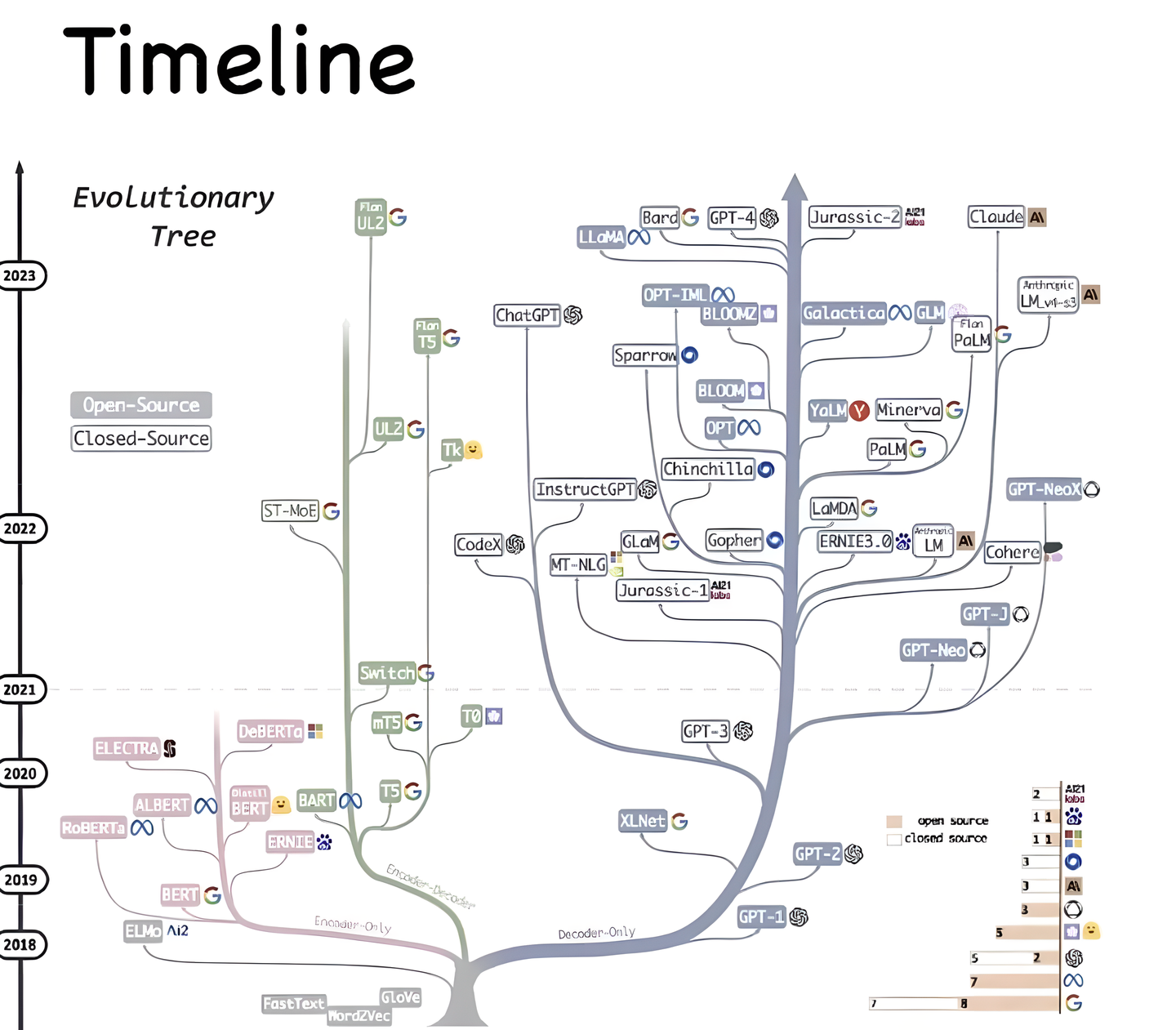
其中比较突出的,之前我觉得是ChatGLM系列 ,不过现在我认为是最近开源的 Qwen 通义千问。
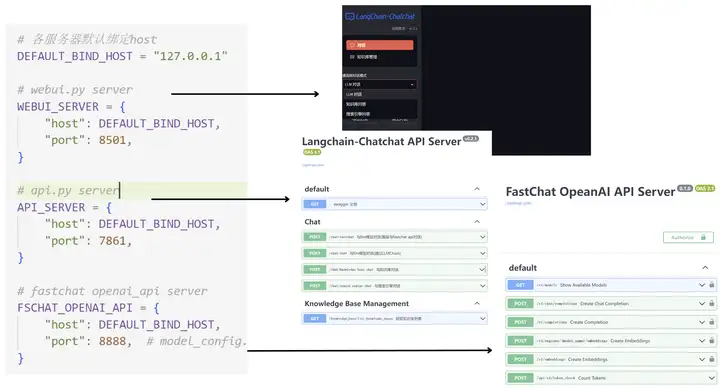
顺便提一句 随着遍地开花的模型,各家都有一个比较好的做法就是去适配一套和OpenAI gpt3.5一致的API 方便大家在测试和搭建不同模型时快速的切换,减少大量阅读接口文档的时间。
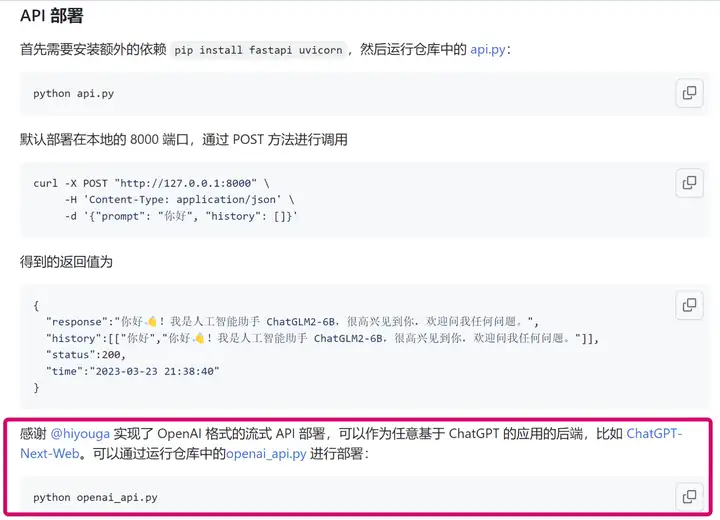
如ChatGLM2 的相关部署代码 https://github.com/THUDM/ChatGLM2-6B/blob/main/openai_api.py
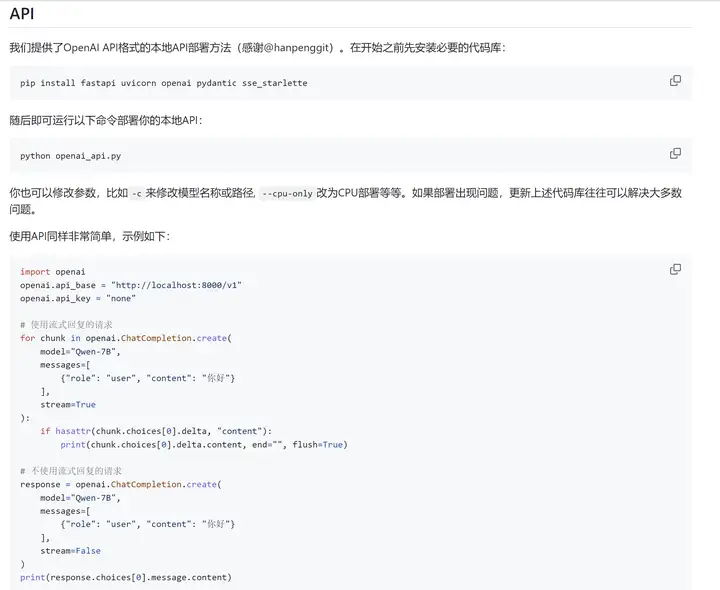
通义千问干脆直接默认API部署代码做成OpenAI API 格式
生态
除了大语言模型本身,相关的基建生态也是我们需要持续关注的。 其中最出名的当属基于相当于LLM应用中间件的 LLama Index 、 Langchain框架 和 AIGC时代数据持久化层的 各大向量数据库。
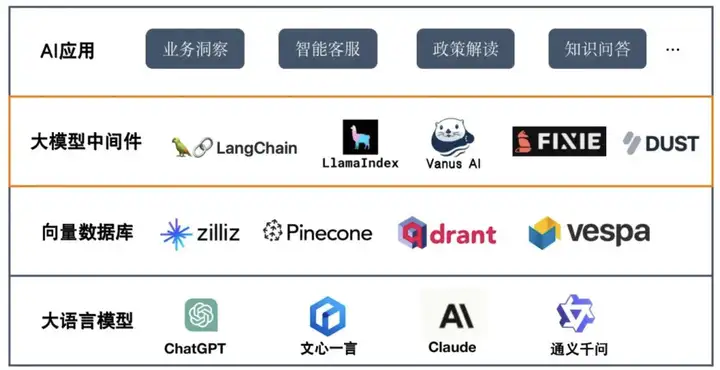
正文
说到知识管理,算是个人研究(折腾)比较久的领域吧,总是觉得工具用的不顺手,研究过很多,其实很多一个痛点就是知识的零散性要怎么解决,要怎么联系,怎么增量沉淀真正发挥作用而不是被堆砌在角落里。几个月前写过一点个人的零散的总结,希望可以抛砖引玉。 不过在大语言模型和现在发达的开发生态来看,相信整个领域不久将会迎来新的转机。
Langchain-Chatchat
是时候介绍今天的主角 Langchain-Chatchat
下面是官方的一些介绍
- 使用 FastChat 提供开源 LLM 模型的 API,以 OpenAI API 接口形式接入,提升 LLM 模型加载效果;
- 使用 langchain 中已有 Chain 的实现,便于后续接入不同类型 Chain,并将对 Agent 接入开展测试;
- 使用 FastAPI 提供 API 服务,全部接口可在 FastAPI 自动生成的 docs 中开展测试,且所有对话接口支持通过参数设置流式或非流式输出;
- 使用 Streamlit 提供 WebUI 服务,可选是否基于 API 服务启动 WebUI,增加会话管理,可以自定义会话主题并切换,且后续可支持不同形式输出内容的显示;
- 项目中默认 LLM 模型改为 THUDM/chatglm2-6b,默认 Embedding 模型改为 moka-ai/m3e-base,文件加载方式与文段划分方式也有调整,后续将重新实现上下文扩充,并增加可选设置;
- 项目中扩充了对不同类型向量库的支持,除支持 FAISS 向量库外,还提供 Milvus, PGVector 向量库的接入;
- 项目中搜索引擎对话,除 Bing 搜索外,增加 DuckDuckGo 搜索选项,DuckDuckGo 搜索无需配置 API Key,在可访问国外服务环境下可直接使用。
效果演示
直观的看看最后的效果
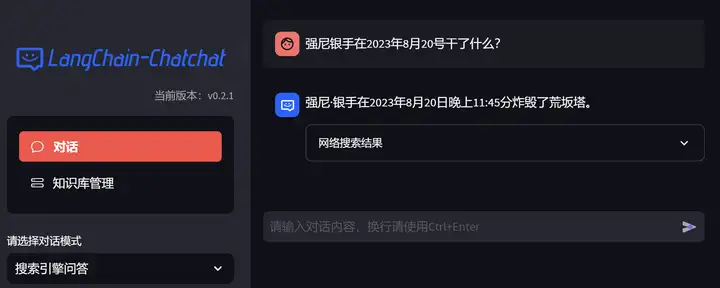
LLM + duckduckgo 搜索引擎 (记得pip install duckduckgo-search)
历史上的今天 让我们看看强尼银手2023/8/20干了些什么
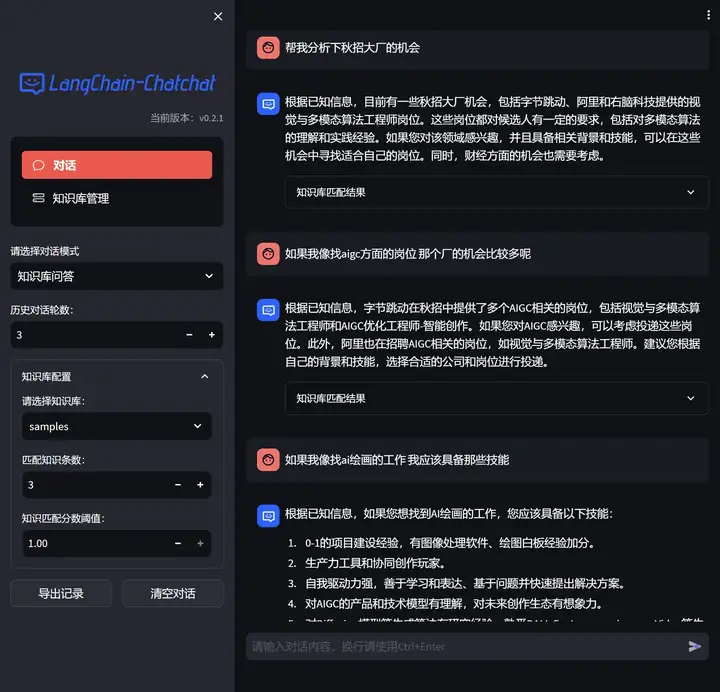
LLM + 本地知识库
架构
其实LangChain-Chatchat 前身是 langchain-chatglm ,即为chatglm 制作的 langchain 组件
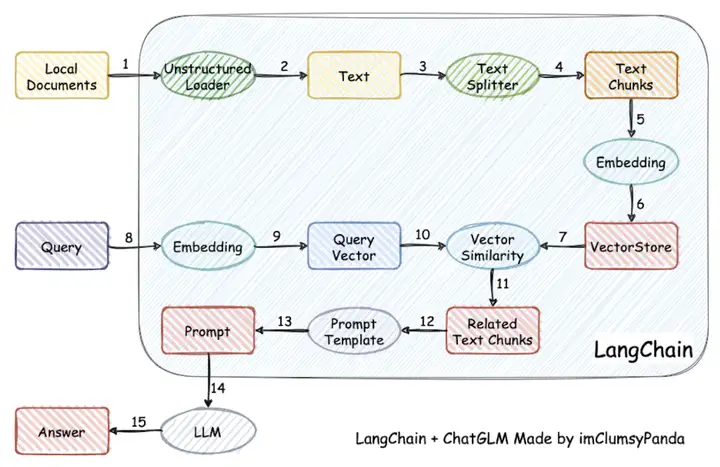
下面是早期项目的流程原理图
简单来说就是把本地的一些文档( doc txt md csv json ...) 先通过一系列处理( 读取 分词 )embedding模型编码成一定数量的高维向量 (下图中 1到6)
而用户原本直接和LLM对话的文本 也会通过embedding 模型编码成高维向量 (下图中 8 9)
然后通过计算余弦相似度的方式 (下图中10和7) 来检索本地文档库中可能提供帮助的相关资料
再和原用户的问题文本 结合 (下图中11)
经过预先我们准备好的提示词模板 Prompt Template 组装成最后的 Prompt 提示词 (下图中12 13)
去问LLM (下图中14 15)
2.0版本在原有基础上
增加了支持的大语言模型 比如我们今天要讲的通义千问 。
增加了支持的向量数据库 比如本文中使用的Milvus。
增加了搜索引擎能力的集成 让LLM能利用外部实时信息 比如本文中使用的DuckDuckGO。
搭建教程
8.23 更新 在Autodl 封装好了镜像 开箱即用 没有gpu和非技术的小伙伴快去看看吧
环境准备
本文使用的系统是windows 下 子系统 WSL2 Linux ubuntu22
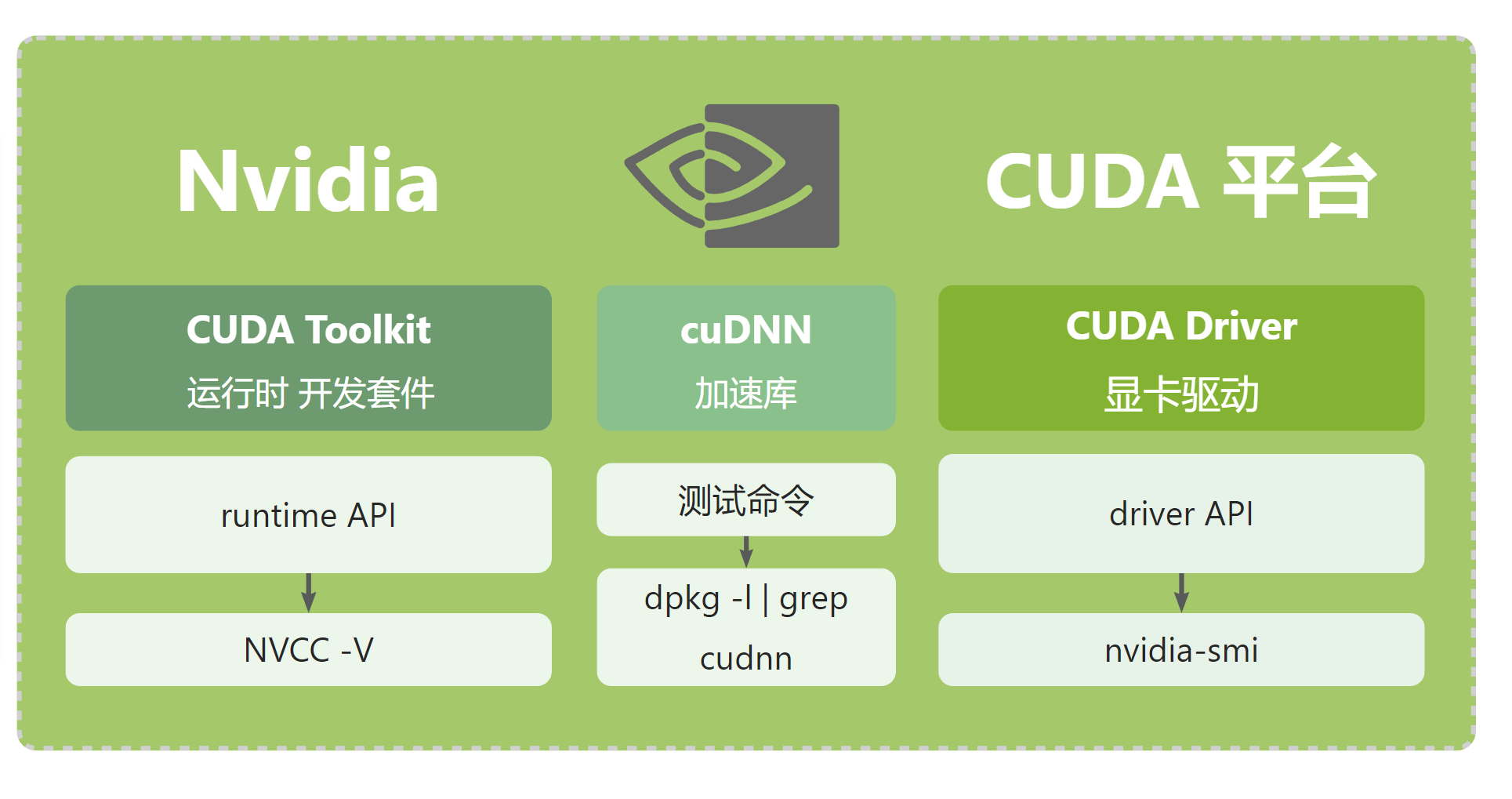
关于wsl2 、cuda pytorch 安装配置 以及ubuntu上一些常用操作可以去看下面两篇文章
通义千问
模型准备
由于我们使用的是 通义千问 Qwen 模型来作为我们的 LLM 基座 所以我们首先得把模型下载到本地
通常开源 LLM 与 Embedding 模型可以从HuggingFace下载。
具体操作可以去下面这篇文章中最后部分查看

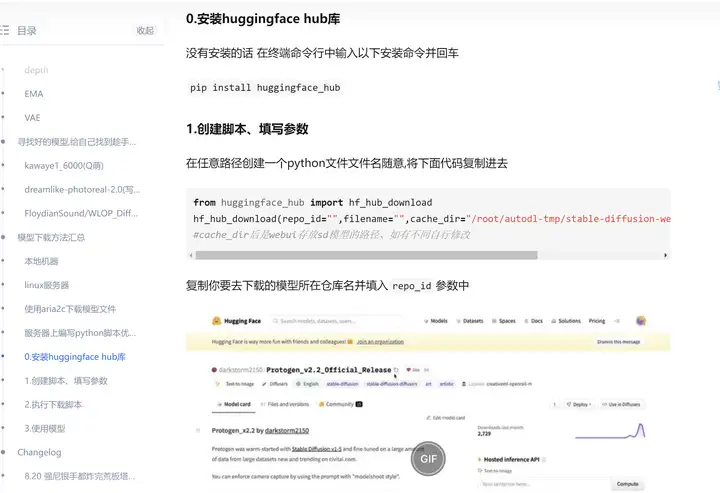
或者直接运行通义千问的仓库的demo代码 Transformers库会自动去下载模型权重到本地
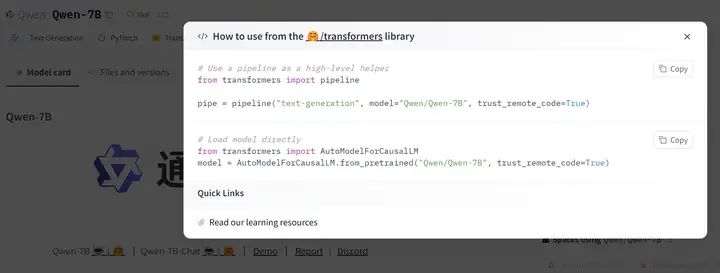
这里有个地方着重强调下 huggingface hub库会默认 把所有下载的文件 放在 ~/.cache/huggingface 路径下统一维护
可如果默认的路径所在的盘空间不够 我们想让huggingface hub换个地方作为下载维护的路径该如何操作呢?
这就要在你当前的conda 环境下添加一个 HF_HOME 环境变量 ,值为你要用来放那些模型的路径
Conda 为不同的环境配置独立的环境添加变量
可以使用conda env命令来管理环境变量。可以使用以下命令将环境变量添加到现有环境中:
conda env config vars set MY_VARIABLE=value --name myenv
MY_VARIABLE value分别替换为你要设置的环境变量名和他的值, myenv 替换成你的环境名
然后,可以使用以下命令激活环境并检查环境变量是否已设置:
conda 激活 myenv
echo $MY_VARIABLE
这样,每次激活“myenv”环境时,都会自动设置“MY_VARIABLE”环境变量。
Langchain-Chatchat
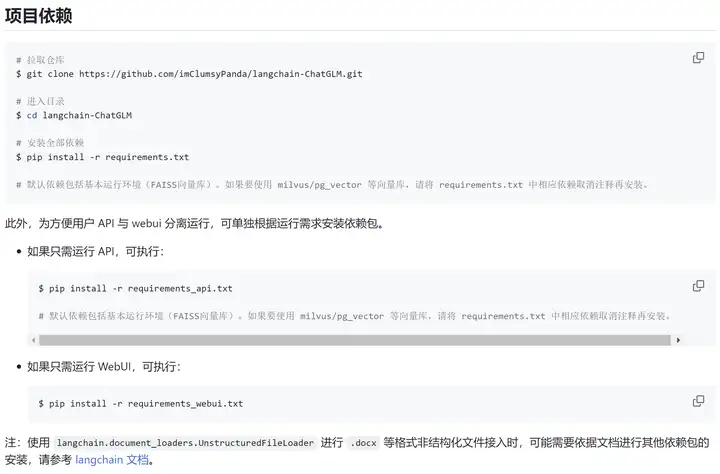
项目下载 依赖安装
https://github.com/chatchat-space/Langchain-Chatchat
配置文件修改
这是最坑的部分 建议仔细阅读
复制模型相关参数配置模板文件 configs/model_config.py.example 存储至项目路径下 ./configs 路径下,并重命名为 model_config.py。
复制服务相关参数配置模板文件 configs/server_config.py.example 存储至项目路径下 ./configs 路径下,并重命名为 server_config.py。
详细讲解
model_config.py
embedding模型 、llm模型、 向量数据库 、 prompt template (后面这俩我们先使用默认即可)
embedding模型

llm模型
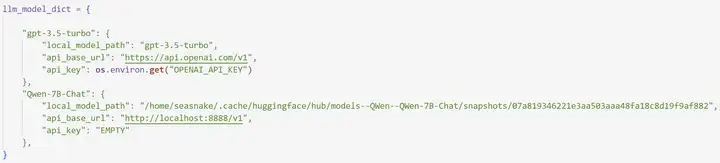
将local_model_path 的值改为你机器上存放千问模型的路径
别的api_base_url 和api_key 和下图保持一致即可
server_config.py
server_config 里主要是该项目几个进程监听的端口的配置以及多GPU情况下的配置 我们这边直接用默认的即可
知识库初始化
当前项目的知识库信息存储在数据库中,在正式运行项目之前请先初始化数据库
python init_database.py --recreate-vs
启动
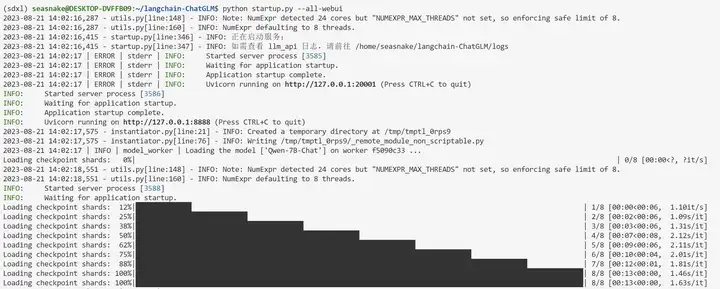
运行下面命令 启动所有的组件
python startup.py --all-webui
依次启动
除了上面的一键启动 也可以单独启动下面的组件
fastchat 部署的 LLM API
Langchain-Chatchat API
基于Streamlit 的WebUI
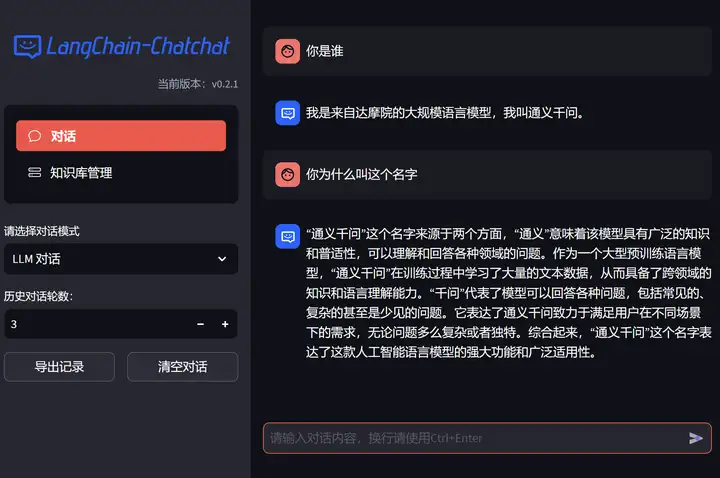
然后我们就可以通过访问 http://127.0.0.1:8501/ 来使用我们的大语言智能助手啦
向量数据库进阶教程
前面的部分介绍了基本版的 langchain chatchat 使用 可如果我们的知识库有很庞大的规模 默认的Faiss 可能会有点吃力 ,所以下面带大家探索怎么修改为 milvus 向量数据库 (还可以改成 postgresql 的向量数据库插件pg流程类似 就不介绍了)
之所以刚才解释model config的部分没讲是因为这部分比较坑
一是milvus和langchain本身 属于快速迭代期 版本多变
二是 现在milvus 必须用docker K8S 环境部署 (当然也可以从源码编译 但gcc cmake go等工具 过于繁琐)这对我们常用的 GPU云服务器 类似于Autodl 非常不友好 因为GPU算力服务器基本都不支持docker(因为这些厂家本身搭建这些paas iaas的系统就是基于docker网络来编排调度 )
三是 存在一个bug 需要我们到langchain chatchat源码里去修改
下面开始啃下这块硬骨头
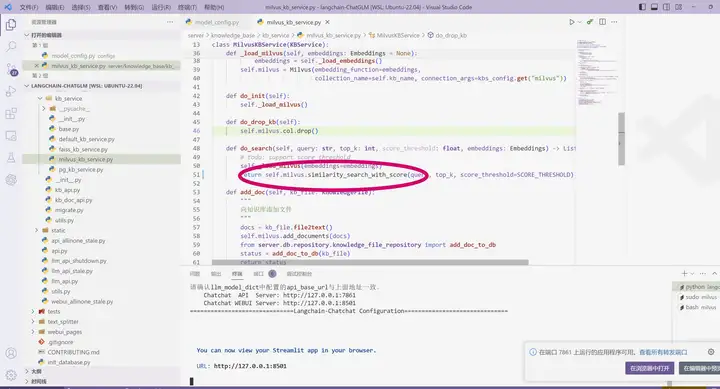
将langchain-ChatGLM/server/knowledge_base/kb_service/milvus_kb_service.py 里的do_search 下的similarity_search 改为 similarity_search_with_score 记得保存
然后去用docker-compose装milvus 数据库 没有安装docker 的得先装docker 有docker的先确保docker守护进程后台开启 然后我们就开始倒腾milvus数据库了 wsl2下docker安装教程可以看下下面的教程

项目里已经内置了 docker 构造的相关文件文件
我们cd 到 milvus路径下 运行下面命令 拉取构造milvus相应容器
sudo docker-compose up -d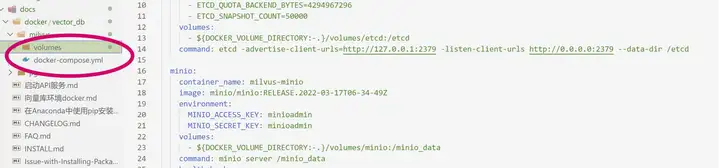
上面的命令运行后 ,我们会看到三个docker 容器运行起来 这些就证明milvus已经启动并可以接收服务了

然后去配置文件里把向量数据库选项改成从faiss 改成 milvus
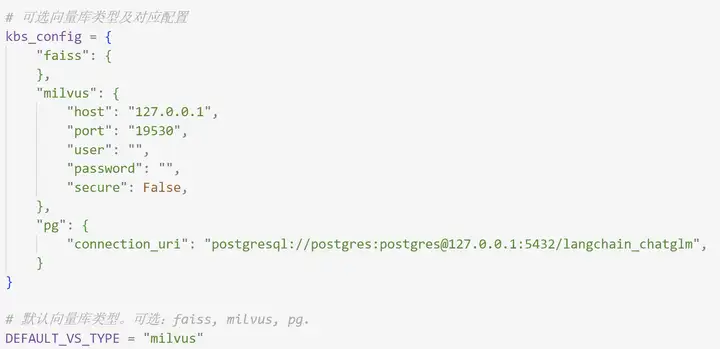
万事俱备 赛博飞升
还是使用刚才说过的 python startup.py --all-webui 命令启动
为了测试 我们可以先去 webui里新建一个数据库测试一下 如下图所示
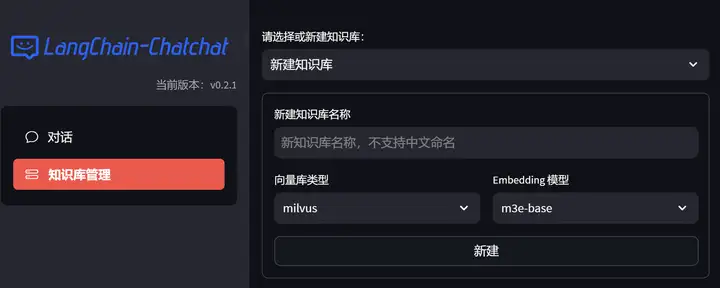
经典彩蛋环节Lucy 虽迟但到
边缘行者 wiki 上把lucy的信息剪裁下来 markdown
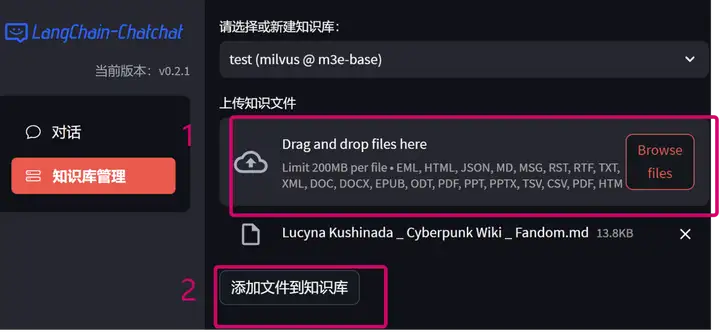
上传到知识库
开始验收成果啦
选择对话模式 选择知识库 开问!
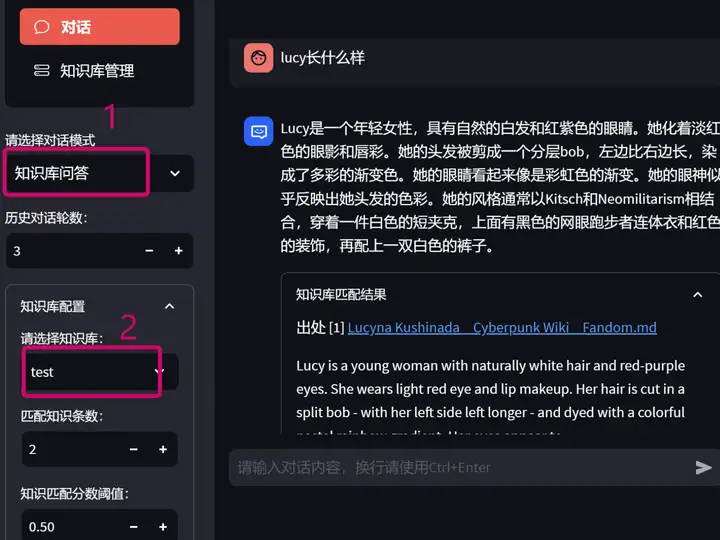
完美
联动一波之前stablediffusion训练成果

milvus可视化管理工具 attu
注意版本问题!由于官网上下载速度慢的离谱 传到了百度网盘一份langchain-chatchat 能适配的 2.2版本
https://pan.baidu.com/s/1Vju4LSFzSMzGVKwuf6-YJA?pwd=d8vg
安装下来安装后
默认不用输用户名 密码 直接connect
进来之后就可以看到具体是怎么存在数据库里的
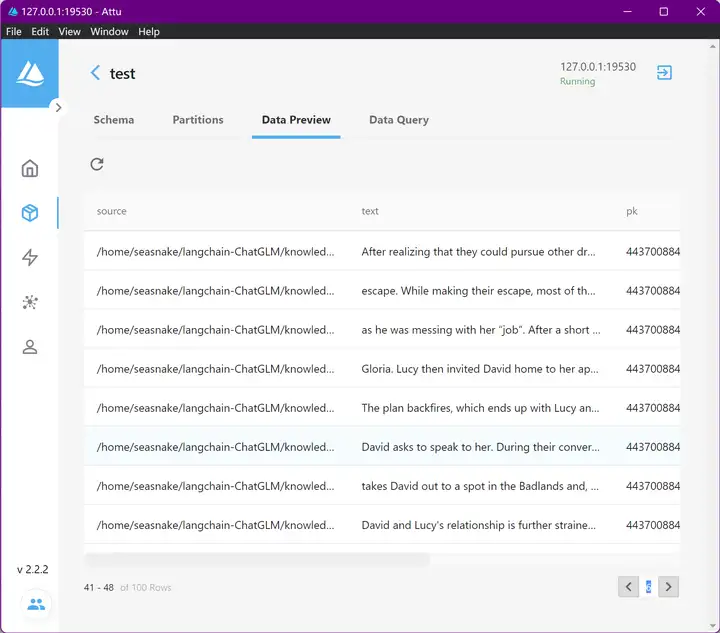
来点三连吧 ( ´◔︎ ‸◔︎`)
8.23 更新 在Autodl 封装好了镜像 开箱即用 适合没有gpu和没时间的小伙伴
8.31更新 通义千问-多模态对话版本 GPT4的平替

参考
- ^moss开源地址 https://github.com/OpenLMLab/MOSS
- ^ChatGLM项目地址 https://github.com/THUDM/ChatGLM-6B
- ^ChatGLM2 https://github.com/THUDM/ChatGLM2-6B
- ^百川 https://github.com/baichuan-inc/Baichuan-7B
- ^Chinese LLama2 https://zhuanlan.zhihu.com/p/645103186
- ^Qwen https://github.com/QwenLM/Qwen-7B/blob/main/README_CN.md