Stable Diffusion是一个文本到图像的潜在扩散模型,由CompVis、Stability AI和LAION的研究人员和工程师创建。它使用来自LAION-5B数据库子集的512x512图像进行训练。使用这个模型,可以生成包括人脸在内的任何图像,因为有开源的预训练模型,所以我们也可以在自己的机器上运行它,如下图所示。

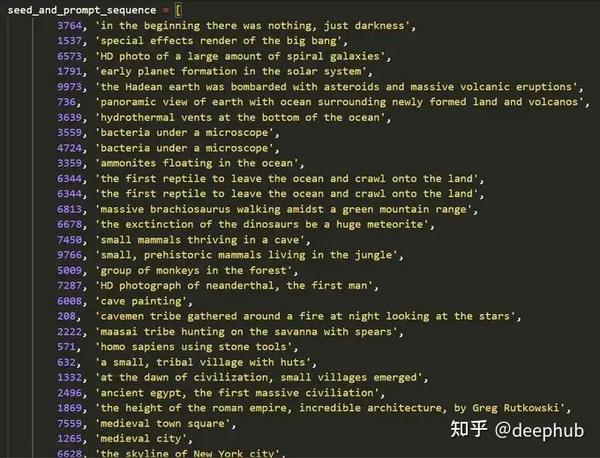
如果你足够聪明和有创造力,你可以创造一系列的图像,然后形成一个视频。例如,Xander Steenbrugge使用它和上图所示的输入提示创建了下面这段令人惊叹的《穿越时间》视频。
以下是他用来创作这幅创造性艺术作品的灵感和文本:
本文主要介绍什么是Stable Diffusion。
Stable Diffusion
Stable Diffusion是一种机器学习模型,它经过训练可以逐步对随机高斯噪声进行去噪以获得感兴趣的样本,例如生成图像。
扩散模型有一个主要的缺点就是去噪过程的时间和内存消耗都非常昂贵。这会使进程变慢,并消耗大量内存。主要原因是它们在像素空间中运行,特别是在生成高分辨率图像时。
Latent diffusion通过在较低维度的潜空间上应用扩散过程而不是使用实际的像素空间来减少内存和计算成本。所以Stable Diffusion引入了Latent diffusion的方式来解决这一问题计算代价昂贵的问题。
来自:deephup