Minigpt-4
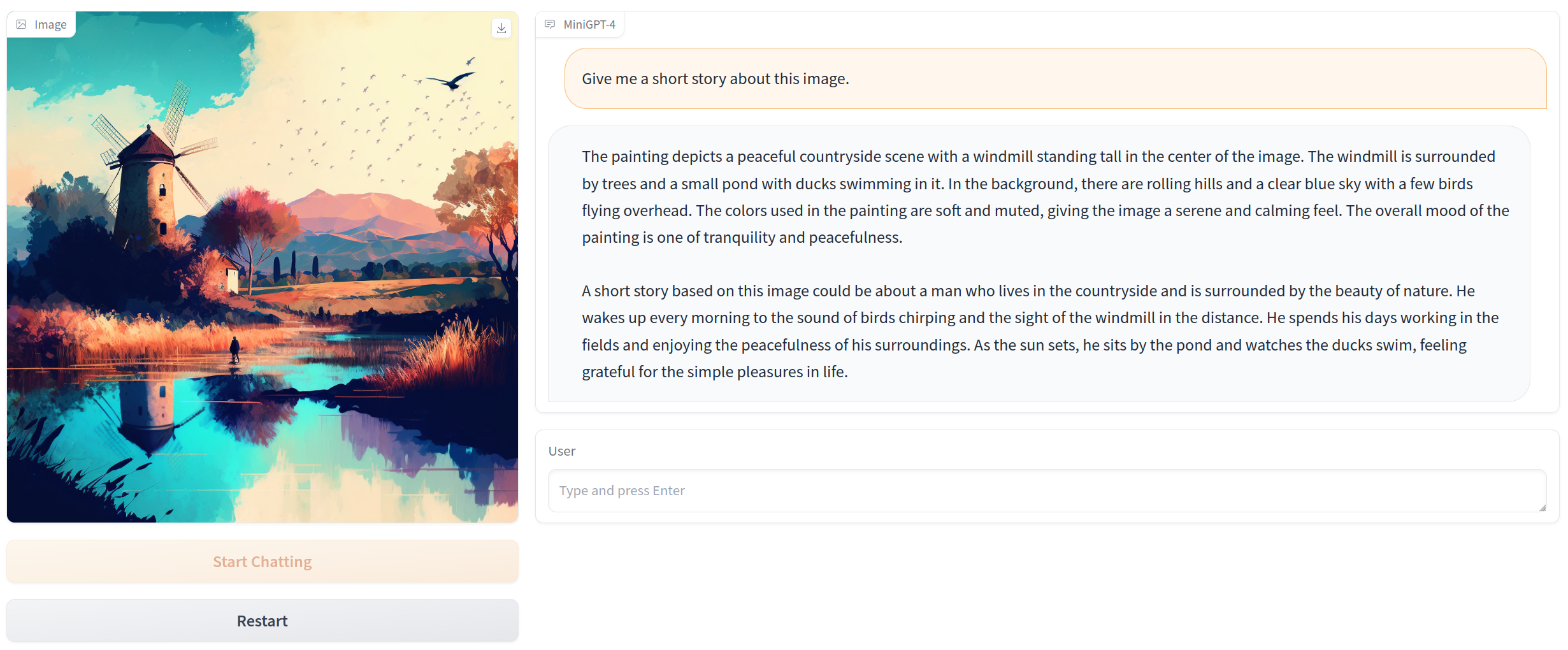
MiniGPT-4 is a tool that enhances vision-language understanding by combining a frozen visual encoder with a frozen large language model (LLM) using just one projection layer. This tool is capable of generating detailed image descriptions, creating websites from hand-written drafts, writing stories and poems inspired by given images, providing solutions to problems shown in images, and teaching users how to cook based on food photos. MiniGPT-4 is highly computationally efficient, as it only requires training the linear layer to align the visual features with the Vicuna using approximately 5 million aligned image-text pairs.
アクセス:
210.3K
国:
United States
議論する