Promptr
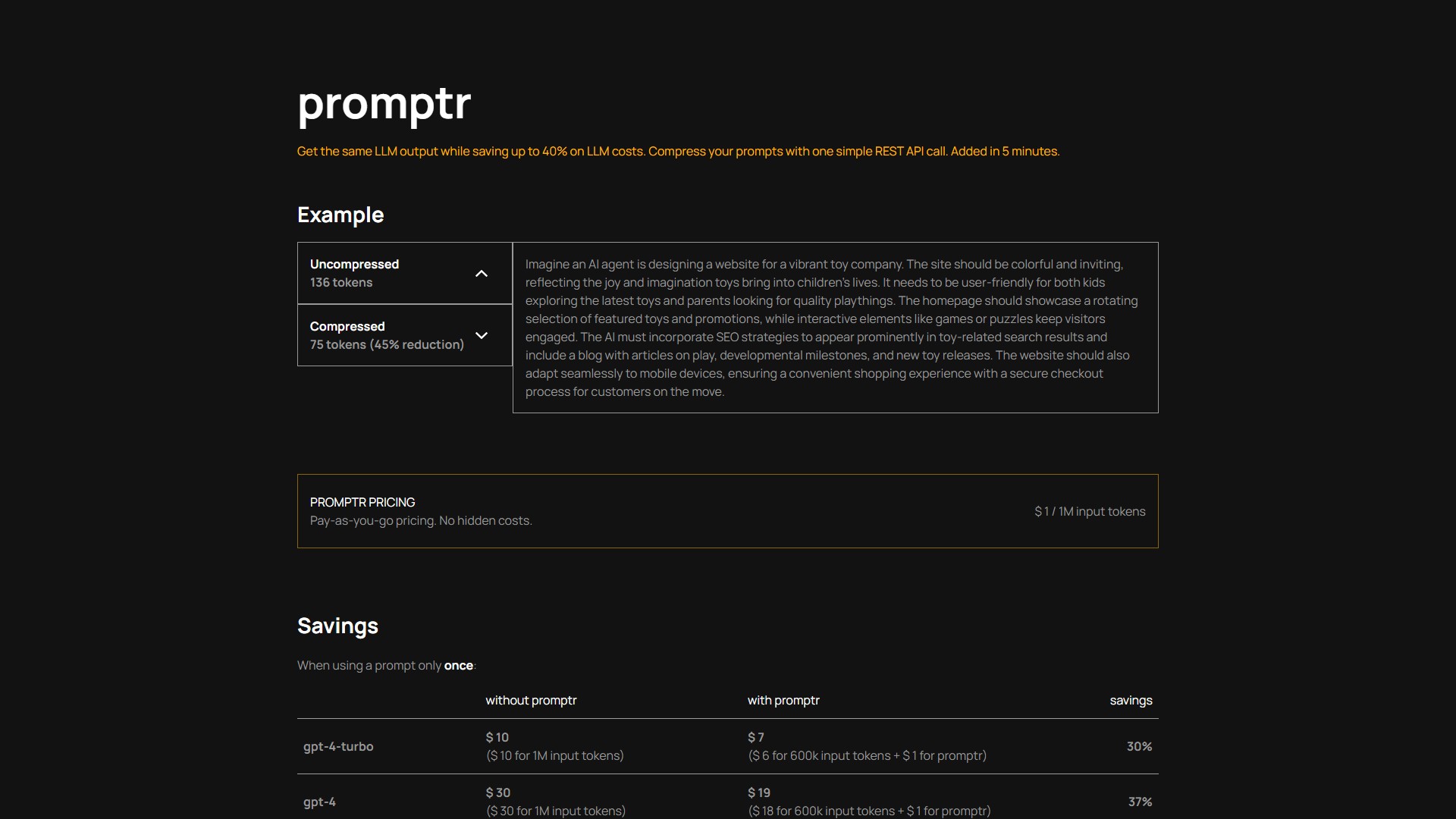
Core Functionality: Compresses Large Language Model (LLM) prompts via a single REST API call, saving up to 40% on LLM costs while getting the exact same LLM output.
Main Features:
- Quick Integration: Can be added in just 5 minutes.
- High Compression Rate: The default compression ratio is 0.6 (40% reduction), and it supports customized compression ratios, such as
<promptr ratio="0.5">for 50% compression or<promptr ratio="0.8">for 20% compression. - Uncompressed Sections: Supports using the
<promptr compress="false">tag to specify text sections that should not be compressed; uncompressed sections are not billed.
Usage Instructions & API Support:
Provides a single API endpoint (http://promptr.me/compress-prompt) and supports quick integration in multiple programming languages:
- curl: Send a POST request with the Prompt in JSON format.
- Python: Make a POST request using the
requestslibrary. - JavaScript: Make a POST request using the
fetchAPI. - C#: Make an asynchronous POST request using
HttpClient. Headers must includeaccept: text/plain,token: YOUR-API-TOKEN, andContent-Type: application/.
Target Users: Developers, enterprises, and AI application builders who require extensive LLM API calls, especially suitable for scenarios where the same prompt is reused multiple times.
Core Advantages:
- Significant Cost Reduction: When reusing a prompt 100x, using Promptr saves 40% on GPT-4-Turbo and GPT-4. Even when using a prompt only once, it saves 30% on GPT-4-Turbo and 37% on GPT-4.
- Lossless Output: The compressed prompt yields the same LLM output as the uncompressed version.
Pricing Model & Cost: Uses Pay-as-you-go pricing with no hidden costs. Promptr costs $1 per 1M input tokens. For example, using GPT-4 ($30 per 1M input tokens) and reusing a prompt 100x: without Promptr, the cost is $3,000; with Promptr, the LLM cost drops to $1,800 (for 600k input tokens) plus $1 for Promptr, totaling $1,801, which is a 40% saving.
Comment